- +1
AI存在偏見和歧視,算法讓用戶喜好趨同?科學家給出了證據(jù)
或許你已經(jīng)注意到了,當你在電影評分網(wǎng)站給剛看完的電影評完分后,網(wǎng)站后續(xù)給你推薦的影片風格會與你看完的電影類似。舉個更常見的例子,當你在購物網(wǎng)站搜索過某樣物品后,第二天推薦頁面上顯示的都是類似款。
人工智能可以幫助商家獲得客戶喜好,但同時也在逐漸根據(jù)用戶的反饋,形成喜好偏見,讓用戶的需求同化。不僅如此,在人臉識別領(lǐng)域,算法自帶的歧視和偏見導致的問題,已經(jīng)引發(fā)了諸多爭議。
近日,來自多所大學學者的研究結(jié)果為上述的偏見和歧視提供了證據(jù)。他們的研究論文目前已在預印本網(wǎng)站Arxiv上發(fā)布。
算法推薦系統(tǒng)會放大偏見,并讓用戶喜好趨同
推薦系統(tǒng)的本質(zhì)是一種基于產(chǎn)品內(nèi)容或用戶行為的信息過濾。如今,我們用的很多應用程序和網(wǎng)站都嵌有算法推薦系統(tǒng)。假如你在某視頻網(wǎng)站給一部電影打了高分,那么系統(tǒng)就會為你推薦更多同類型的電影。如果你給系統(tǒng)推薦的電影也打了分,系統(tǒng)就會將你的反饋行為添加到系統(tǒng)中,這就是一種反饋循環(huán)。
但是推薦算法會受到流行性偏見(popularity bias)的影響。流行性偏見是指,一些流行的項目會被經(jīng)常推薦,而其他項目會被忽略。在上面的例子中,一些電影被更多的人喜愛,獲得了更高的評分,就屬于流行的項目,或者可以叫做熱門項目,這些項目會被更多推薦給用戶,這就是流行性偏見。
流行性偏見的產(chǎn)生一部分源于訓練數(shù)據(jù)本身存在不同的流行度,另一部分原因來自推薦算法。隨著時間的推移,這種流行性偏見將會被加強。因為如果用戶在反饋循環(huán)中不斷為熱門電影打高分,這些電影就變得更熱門,被推薦的幾率也就更大。
為了研究反饋循環(huán)對推薦系統(tǒng)放大偏見和其他方面的影響,來自埃因霍溫科技大學、德保羅大學和科羅拉多大學博爾德分校的研究人員在一個電影數(shù)據(jù)集上使用三種推薦算法進行了仿真,模擬推薦系統(tǒng)的交互過程。
作為研究數(shù)據(jù)的MovieLens 1M數(shù)據(jù)集包含了6040個用戶對3706部電影給出的1000209個評分,分數(shù)范圍在1-5之間。研究人員使用的三種推薦算法分別是:基于用戶的協(xié)同過濾(UserKNN)、貝葉斯個性化排序(BPR)和一種向所有人推薦最流行產(chǎn)品的算法MostPopular。
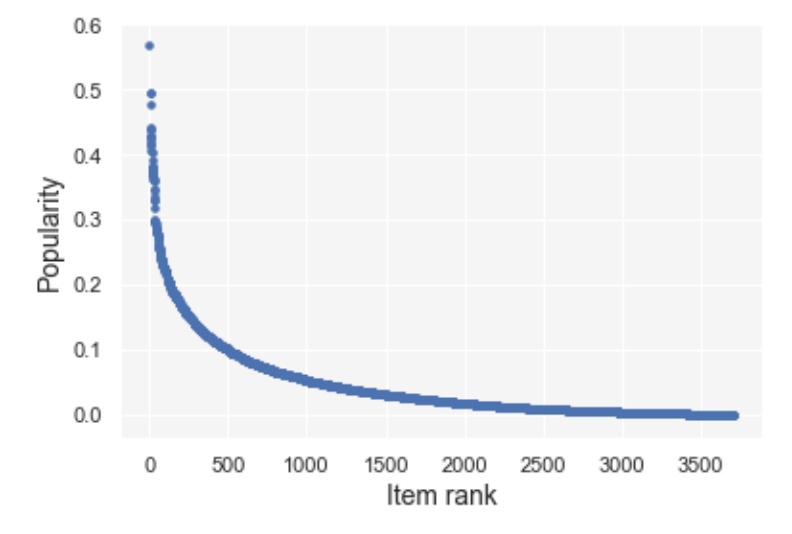
MovieLens數(shù)據(jù)集的初始流行性分布
通過使用這些數(shù)據(jù)和算法進行迭代——系統(tǒng)不斷為用戶生成推薦列表,用戶又不斷對推薦列表中的項目進行打分,研究人員發(fā)現(xiàn),隨著時間的推移,三種算法下的數(shù)據(jù)平均流行度都有所上升,但總體多樣性呈現(xiàn)下降,這也就證明了推薦系統(tǒng)在反饋循環(huán)后的偏見被放大。
流行性偏見的放大還改變了系統(tǒng)對用戶興趣的判斷。在所有的推薦算法中,用戶的偏好與其初始偏好之間的偏差隨著時間的推移而增加。也就是說,這將導致推薦系統(tǒng)為用戶做出的推薦越來越偏離用戶的真實喜好,系統(tǒng)推薦給你的電影將不再符合你的口味。
除此之外,由于推薦系統(tǒng)的偏見被放大,用戶幾乎只能接觸到流行度高的項目,只能看到那些被更多人打了高分的熱門電影。于是,在推薦系統(tǒng)中他們的偏好都會向一個共同的范圍集中,這就表現(xiàn)為用戶偏好的同質(zhì)化。而反饋循環(huán)造成的偏見對少數(shù)群體用戶的影響更大。
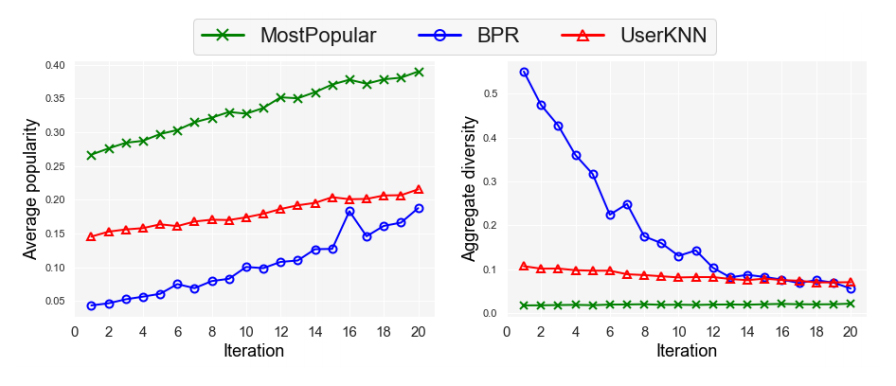
隨著迭代次數(shù)增加,項目平均流行度上升(左),總體多樣性下降(右)
“解決算法偏見的方法變得至關(guān)重要。因為如果處理不當,隨著時間的推移,推薦系統(tǒng)中一個很小的偏差也可能會被極度放大。”研究人員在論文結(jié)尾處寫道。
人臉識別用于訓練的數(shù)據(jù)存在巨大偏差
針對人臉識別算法帶來的偏見越來越受到關(guān)注。例如,能將模糊照片清晰化的PULSE算法將美國前總統(tǒng)奧巴馬的模糊照片“還原”出了一張白人面孔,在全美BLM運動(Black Lives Matter,黑人的命也是命)如火如荼的背景下,就引發(fā)了巨大的爭議。

圖片來源:Twitter網(wǎng)友@chicken3gg
人臉識別領(lǐng)域里出現(xiàn)算法偏差和歧視,一個重要原因是用于訓練的數(shù)據(jù)集存在很大的偏差性。來自劍橋大學和中東科技大學的研究人員就從兩個用于識別人臉表情的數(shù)據(jù)集中找到了證據(jù)。
這兩個數(shù)據(jù)集分別為:RAF-DB和CelebA。其中,RAF-DB包含來自互聯(lián)網(wǎng)的數(shù)以萬計的圖片,這些圖片包括面部表情和屬性注釋,而CelebA擁有202599張圖像,包含10177人的4??0種屬性注釋。
為了確定兩個數(shù)據(jù)集存在偏差的程度,研究人員對隨機子集進行了采樣,并裁剪了圖像,以使面部在方向上保持一致。然后,他們使用分類器來衡量準確性和公平性。
理論上來說,為了讓算法保持準確和公平,這個分類器應在整個過程中提供不同的人口群體的相似結(jié)果。但實際情況并非如此。
在RAF-DB數(shù)據(jù)庫中,絕大多數(shù)的圖片來自年齡在20-39歲之間的白人。從具體的數(shù)據(jù)來看,這些圖片有77.4%來自白人,15.5%來自亞裔,而只有7.1%來自非洲裔美國人;在性別方面,女性為56.3%,男性為43.7%;在年齡上,超過一半的圖片來自20-39歲的年輕人,3歲以下和70歲以上的人甚至少于10%。
為進一步研究數(shù)據(jù)庫存在偏見的程度,研究人員分別使用了三種算法對數(shù)據(jù)庫的準確性和公平性進行評估。結(jié)果發(fā)現(xiàn),在準確性方面,RAF-DB數(shù)據(jù)庫對少數(shù)族裔的識別準確性低于白人;在公平性方面,性別屬性相對更公平,為97.3%,種族和年齡的公平性相對較低,為88.1%和77.7%。
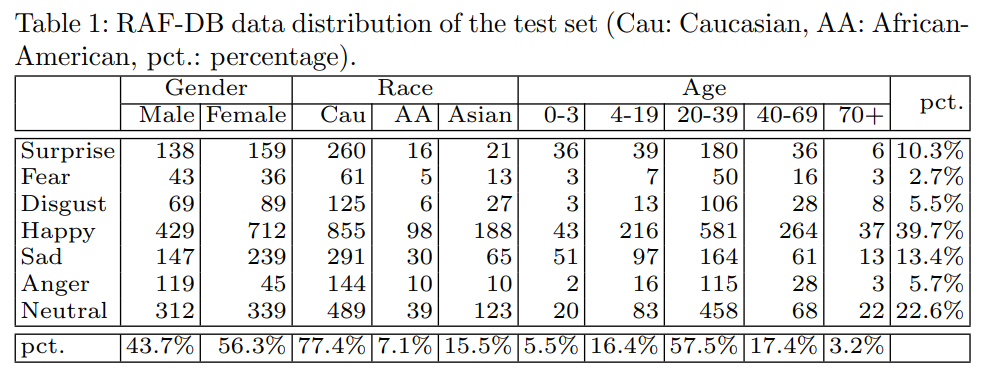
RAF-DB數(shù)據(jù)庫中的數(shù)據(jù)分布
而在CelebA數(shù)據(jù)庫的圖片來源中,女性比例為61.4%,而男性只有38.6%。在年齡上,年輕人占75.7%,明顯超過了占比24.3%的老年人。
在準確性方面,CelebA數(shù)據(jù)庫對年輕女性的準確率為93.7%,但對老年男性的準確性較低,為90.7%。而該數(shù)據(jù)庫在性別和年齡方面的公平性表現(xiàn)都較好,分別為98.2%和98.1%。
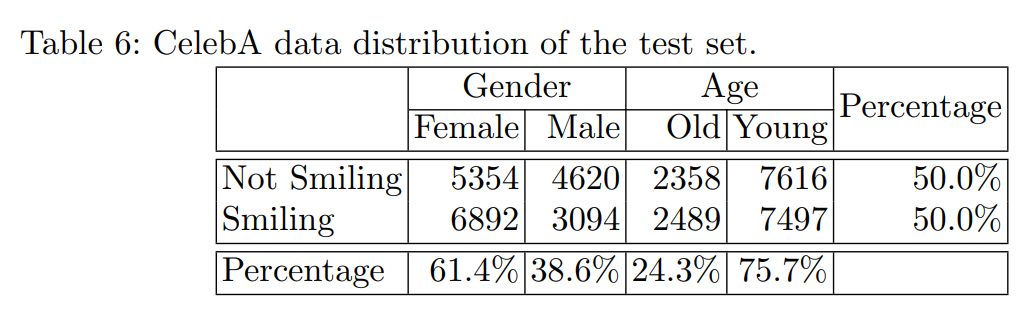
CelebA數(shù)據(jù)庫中的數(shù)據(jù)分布
許多公司曾用人臉識別軟件給面試者的情緒打分,如果整個系統(tǒng)都是有偏見的,對于面試者來說就意味著不公平。面部表情數(shù)據(jù)集中偏見的存也凸顯了監(jiān)管的必要性。如何用法律防止技術(shù)濫用,成為未來這一領(lǐng)域里值得思考的問題之一。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯(lián)網(wǎng)新聞信息服務許可證:31120170006
增值電信業(yè)務經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報業(yè)有限公司

