- +1
博弈論速成指南:那些融入深度學習的經典想法和新思路
機器之心
選自TowardsDataScience
作者:Jesus Rodriguez
機器之心編譯
參與:魔王、杜偉
隨著人工智能的發展,博弈論迎來了復興。關于博弈論,數據科學家需要了解哪些經典思想和新思路呢?本文作者就這些問題一一展開了分析。通過此文,相信讀者會對博弈論的概念和分類有更清晰的理解。

博弈論是具備激勵機制的概率。
游戲在人工智能發展過程中起到關鍵作用。對于初學者而言,游戲環境在強化學習或模仿學習等領域中逐漸成為流行的訓練機制。理論上,任何多智能體 AI 系統都要經歷玩家之間的游戲化交互。構建游戲原則的數學分支正是博弈論。在人工智能語境和深度學習系統語境下,要想使多智能體環境具備一些必備的重要能力,博弈論必不可少。在多智能體環境中,不同的 AI 程序需要交互或競爭才能達成目標。
博弈論的歷史與計算機科學史密不可分。目前博弈論領域中的許多研究可以追溯至阿蘭·圖靈、馮·諾伊曼這些計算機科學先驅的工作。因電影《美麗心靈》而聞名于世的納什均衡(Nash equilibrium)是現代系統中很多 AI 交互的基礎。但是,利用博弈論原則多次建模 AI 宇宙超出了納什均衡的范疇。想理解如何利用博弈論構建 AI 系統,最好先理解我們在社會或經濟互動中常遇到的博弈類型。
我們每天參與數百種基于游戲動態(game dynamics)的交互。但是,游戲化環境的架構與此完全不同,其激勵和參與者目的也不相同。如何將這些原則應用到 AI 智能體建模中呢?這個難題推動 AI 研究某些領域的發展,如多智能體強化學習。
顯然,游戲是博弈論最具可見性的實體,但它遠遠不是應用博弈論概念的唯一空間。也就是說,還有很多其他領域也受到博弈論和 AI 的共同影響。大多數需要多個「參與者」合作或競爭才能完成任務的場景都可以利用 AI 技術進行游戲化和改進。盡管之前的陳述是一種泛化,但我認為它傳達出了一個信息:博弈論和 AI 是一種思考和建模軟件系統的方式,而不只是一種技術。
利用博弈論的 AI 場景應包含不止一個參與者。例如,Salesforce Einstein 這類銷售預測優化 AI 系統就不是應用博弈論原則的完美場景。但是,在多智能體環境中,博弈論又有明顯不同。
在 AI 系統中建構游戲動態需要兩步:

機制設計:逆博弈論(inverse game theory)主要為一組智能參與者設計游戲。拍賣就是機制設計的經典案例。
那么 AI 時代的數據科學家又需要了解哪些博弈呢?這些博弈彼此之間是否存在著聯系呢?本文作者、Invector Labs 首席科學家兼執行合伙人 Jesus Rodriguez 對此發表了自己的看法。

數據科學家應該知道的 5 種博弈
假設我們正在構建一個需要多個智能體互相合作競爭才能完成特定目標的 AI 系統,即博弈論的經典場景。自 20 世紀 40 年代誕生以來,博弈論專注于建模最常見的交互模式,現在我們每天在多智能體 AI 系統中看到的就是它們。理解環境中不同類型的游戲動態是設計高效游戲化 AI 系統的關鍵元素。從較高層次來看,五元素標準有助于理解 AI 環境中的游戲動態,即對稱 vs 非對稱、完美信息 vs 非完美信息、合作 vs 非合作、同時 vs 序列和零和 vs 非零和。下面將一一展開介紹。
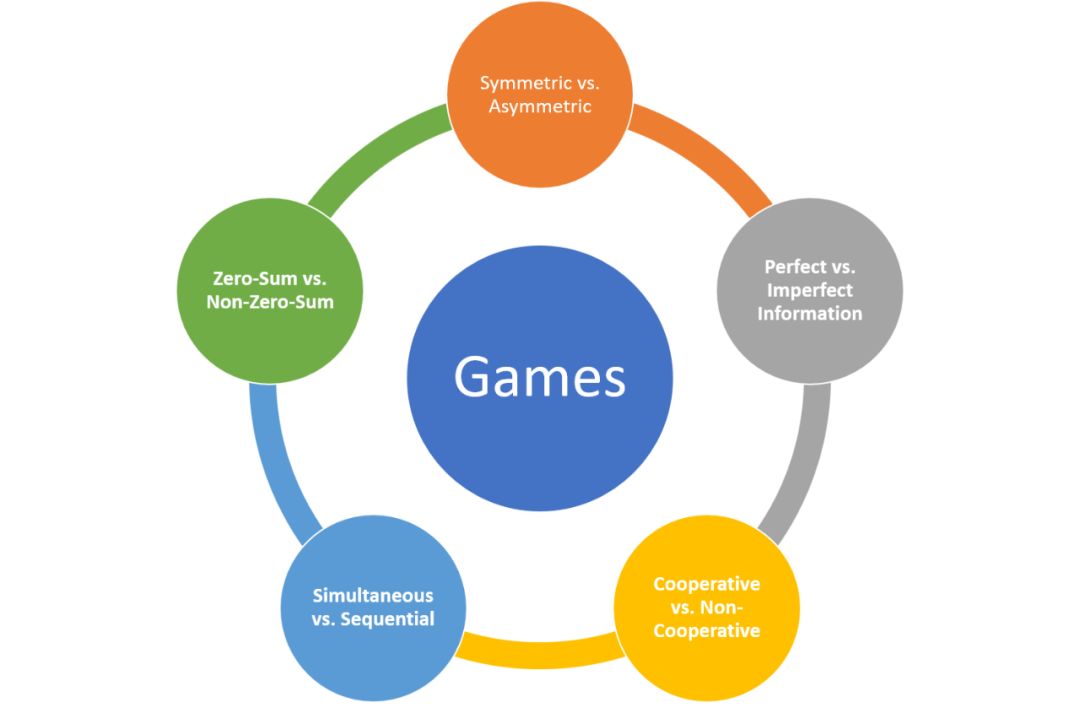
對稱 vs 非對稱
最簡單的一種博弈分類方式是根據對稱性進行分類。在對稱博弈環境里,每個玩家具備同樣的目標,結果僅取決于策略。國際象棋就是一種經典的對稱博弈。我們在現實世界中遇到的很多場景缺少對稱的數學優雅性,因為參與者通常目標不同,甚至還存在沖突。商務談判則屬于非對稱博弈,參與各方目標不同,并從不同的角度來評估結果(例如,贏得合同 vs 最小化投資)。
完美信息 vs 不完美信息
另一種重要的博弈分類方式基于可獲取信息類型。完美信息博弈指每個玩家都能夠看到其他玩家的行動,例如國際象棋。在很多現代交互的環境中,每個玩家的行動是對別人隱藏的,博弈論將這些場景歸類為不完美信息博弈。從撲克等紙牌游戲到自動駕駛汽車,不完美游戲博弈就在我們身邊。
合作 vs 非合作
在合作博弈環境中,不同的參與者可以通過結盟來最大化最終結果。合同談判通常被認為是合作博弈。在非合作博弈環境中,參與者禁止結盟。戰爭是非合作博弈的終極案例。
同時 vs 序列
在序列博弈環境中,每個玩家了解對手之前的動作。棋盤游戲本質上最具序列博弈屬性。在同時博弈場景中,雙方可以同時行動,例如證券交易。
零和 vs 非零和
零和游戲指一方有得其他方必有失,例如棋盤游戲。非零和游戲中,多個玩家可以從其他玩家的動作中獲益。經濟交互中多個參與者合作擴大市場規模就是非零和博弈。
納什均衡
對稱博弈統治 AI 世界,其中大多數基于 20 世紀最著名的數學理論之一:納什均衡。納什均衡以美國數學家 John Forbes Nash 命名。本質上,納什均衡描述了這樣的場景:每個玩家選擇一個策略,當一個玩家不改變策略時,沒有玩家能從改變策略中獲益。

納什均衡是一個優美且強大的數學模型,它可以解決很多博弈論問題,但在一些對稱博弈環境中捉襟見肘。對于初學者而言,納什方法假設玩家具備無限的計算能力,而現實環境中幾乎不存在這種情況。
此外,很多納什均衡模型無法解釋風險概念(常見于大多數非對稱博弈場景,如經濟市場)。因此,很多非對稱博弈場景很難利用納什均衡實現。在多智能體 AI 系統中這一點尤為重要,這需要在解決方案的數學優雅性和實現的可行性中找到合適的平衡。
博弈論中正在影響機器學習的新想法
多智能體 AI 系統是 AI 生態系統中最讓人著迷的領域之一。多智能體系統等領域的近期進展擴展了博弈論的邊界,它依賴該領域中最復雜的思想。作者在下文又列舉了出現在現代機器學習中的博弈論子領域的示例。
平均場博弈
平均場博弈(Mean Field-Games,MFG)是博弈論中比較新的領域。MFG 理論誕生于 2006 年,是 Minyi Huang、Roland Malhamé、Peter Caines、Jean-Michel Lasry 和菲爾茲獎得主 Pierre-Louis Lions 發表的一系列獨立論文中的一篇。
從概念上看,MFG 包含的方法和技術用于研究由「理性博弈方」組成的大群體下的微分博弈。這些智能體不光對自己的狀態(如財富、資產)有偏好,對群體中其他智能體的分布也存在偏好。MFG 理論為這些系統研究泛化納什均衡。
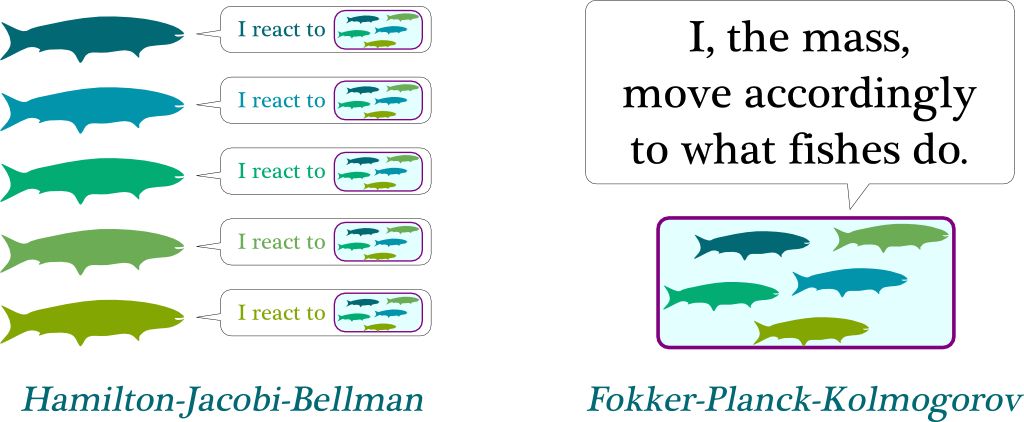
經典的案例是如何讓幾個魚群以比較協調的方式沿相同方向游動。理論上,這種現象很難解釋,不過它基于這一事實:魚對最鄰近魚群的行為有反應。具體而言,每條魚并不關心其他魚,但是它關心附近作為一個整體統一移動的魚群。如果我們用數學術語表述的話,魚對魚群的反應是哈密頓-雅可比-貝爾曼方程(Hamilton-Jacobi-Bellman equation,簡稱 HJB 方程)。而整個魚群的行動是所有魚的動作集合,這對應了福克-普朗克方程(Fokker-Planck-Kolmogorov equation)。平均場博弈理論是這兩個公式的結合體。
隨機博弈
隨機博弈可以追溯至 1950 年代,由諾貝爾經濟學獎獲得者 Lloyd Shapley 提出。從概念上來看,隨機博弈由有限數量的玩家在有限狀態空間中執行,在每個狀態中,每個玩家從有限多的動作中選擇一個;最終動作組合決定了每個玩家的獎勵和下一個狀態的概率分布。

隨機博弈的經典形式是哲學家晚餐問題:有 n + 1 位哲學家 (n ≥ 1) 坐在圓桌旁,圓桌中間有一碗米飯,任意兩位相鄰的哲學家之間有一根筷子,筷子在兩人可及范圍內。由于桌子是圓的,因此筷子的數量與哲學家人數一樣。為了吃到碗中的米飯,每位哲學家需要拿到可及范圍內的兩根筷子。如果一位科學家吃到了,那么他的兩位鄰座就不能同時吃到。哲學家的生活很簡單,只有思考和吃飯,為了生存,哲學家必須一次次地思考和吃飯。該任務就是設計一個使所有哲學家生存下去的機制。

演化博弈
演化博弈論(Evolutionary Game Theory,EGT)從達爾文進化論中獲得靈感。EGT 的起源可以追溯至 1973 年的 John Maynard Smith 和 George R. Price,也可以作為策略來分析,該數學標準可用于預測競爭策略的結果。
從概念上看,EGT 是博弈論概念在如下場景中的應用:通過選擇和復制的進化過程,隨著時間的變化,智能體群體使用不同策略來創建穩定的解決方案。EGT 的主要思想是很多行為涉及群體中多個智能體的交互,任意一個智能體的成果都離不開其策略與其他智能體策略之間的交互。經典博弈論專注于靜態策略(即策略不隨時間變化),而演化博弈論專注于策略隨時間的變化,以及在進化過程中最成功的動態策略。
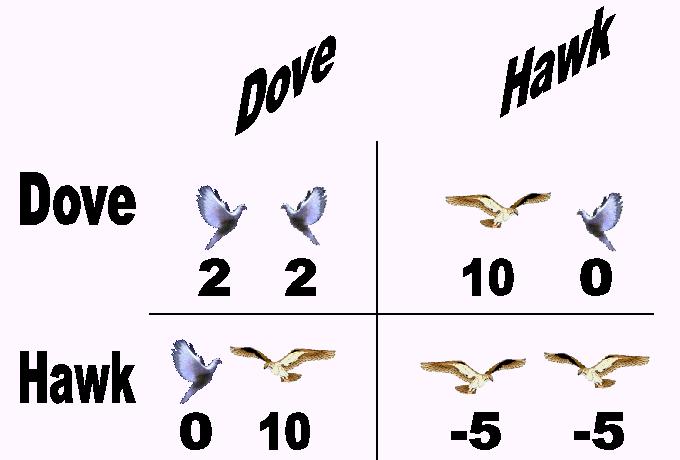
EGT 的經典案例是鷹鴿博弈,即讓鷹和鴿子圍繞可共用資源競賽。在該游戲中,每位選手嚴格遵循以下策略中的一個或全部:
鷹:發起攻擊行為,在受傷或對手后退之前絕不停下。
鴿:如果對手發起攻擊行為,直接撤退。
如果我們假設存在如下情況:1)當兩個個體都發起攻擊行為時,戰斗最終走向結束,二者具備同等受傷概率;2)戰斗成本將個體的健康度降低了某個常量 C;3)當鷹鴿相遇時,鴿子直接逃跑,鷹獲取資源;4)兩只鴿子遇到資源并平分資源,則鷹鴿博弈的健康情況如下所示:
很多案例不需要優化參與者的策略,而是圍繞理智參與者的行為設計游戲,這就是逆博弈論。拍賣被認為是逆博弈論中的主要案例。
總之,隨著人工智能的發展,博弈論正在復興。阿蘭·圖靈或馮·諾伊曼等計算機科學界傳奇人物提出的博弈論原則現在已經是全球某些最智能系統的核心,人工智能近期進展也有助于推動博弈論研究的發展。隨著 AI 繼續進化,我們將看到更多博弈論新想法找到融入主流深度學習系統的方式。
原文鏈接:https://towardsdatascience.com/a-crash-course-in-game-theory-for-machine-learning-classic-and-new-ideas-50e33ba2636d
本文為機器之心編譯,轉載請聯系本公眾號獲得授權。
?------------------------------------------------
加入機器之心(全職記者 / 實習生):hr@jiqizhixin.com
投稿或尋求報道:content@jiqizhixin.com
廣告 & 商務合作:bd@jiqizhixin.com
原標題:《博弈論速成指南:那些融入深度學習的經典想法和新思路》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2024 上海東方報業有限公司

