- +1
全世界網友如何表達“笑”
服老思和同學們 P話

笑聲好像很復雜,即使在現實生活中,似乎也很難分辨出人們的笑背后到底是真心還是假意;放到網上,隔著屏幕,要辨別“笑”背后的情感似乎就更加困難了。“哈哈哈”背后,到底是真的開心,還是在緩解無話可說的尷尬?各類網絡用語和熱搜詞匯層出不窮,還有各類表情包的加持,我們有了更多表達“笑”的形式。于是,有個 The pudding 出品的這個有關“笑”的數據報道。報道由三部分組成,分別從從表達“笑”的語言用法、演變和感知三個方面進行了研究。在你看來,是用“rofl”還是“haha”還是“lolol”表達的開心程度高呢?出品團隊使用了 BigQuery 作為主要的數據分析工具,對來自于 Reddit 的 2019 年 1 月到 2019 年 6 月共 7 億條評論進行文本分析。2019 年上半年最常用來表達“笑”的方式是什么呢?“lol"榮登榜首??

Dai Yi Wan | 戴怡宛
2020 年戛納國際創意節中國臺灣代表隊選拔賽選手,利用 AI 做了一個名叫戴怡宛的女孩子,她的所有特征都來自臺灣:用 10000 張臺灣人的臉做出一個臺灣女孩,碩士論文是寫儒家文化在政府中的影響等。制作團隊甚至為她做了個人履歷表、網站并注冊了 Linkedin 的賬號。她能在向往的國際 NGO 組織找到工作嗎?

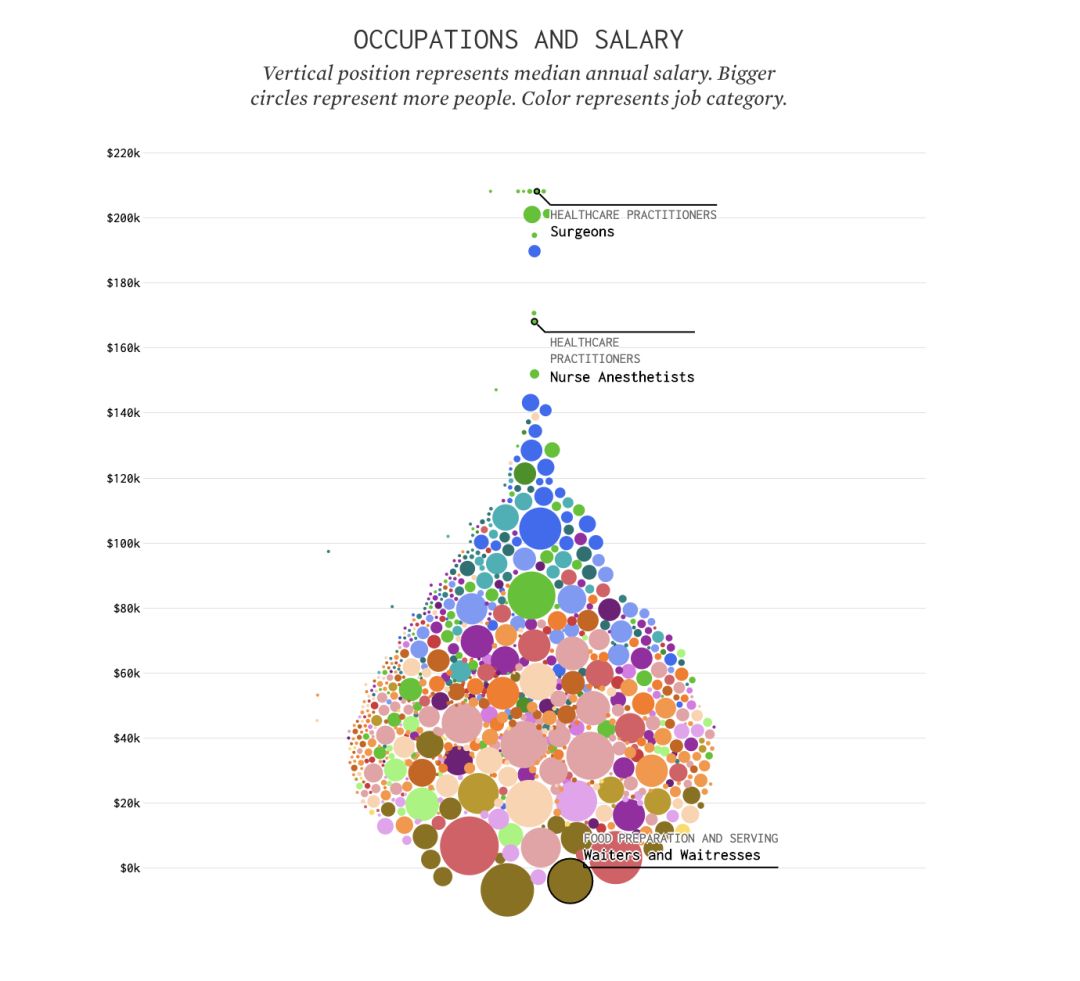
收入和職業
世界上什么哪個職業的工資比較高?哪個職業從事的人數比較多?快來看看你的職業怎么樣吧。圖表中的每個圓圈代表一個職業,圓圈在縱向位置的高低代表不同職業的年薪中位數,圓圈的大小代表從事職業的人數,不同顏色代表不同的職業種類。整個圖表的形狀上窄下寬,果然只有少部分人站在社會森林法則的最頂端啊
。
Magi
你知道最近火爆中文互聯網世界的 Magi 嗎? Magi是什么?來看看官方解釋??:
從前的日色變得慢,車,馬,郵件都慢,一生只夠愛一個人Magi 是由 Peak Labs 研發的基于機器學習的信息抽取和檢索系統,它能將任何領域的自然語言文本中的知識提取成結構化的數據,通過終身學習持續聚合和糾錯,進而為人類用戶和其他人工智能提供可解析、可檢索、可溯源的知識體系。
“Peak Labs”公司近日發布了其人工智能系統 Magi 的公眾版“ magi.com ”。通過這一搜索引擎,用戶輸入關鍵詞,即可獲取 Magi 從互聯網文本中自主學習到的結構化知識和網頁搜索結果,每個結構化結果后面都會附上來源鏈接和其可信度評分。“ magi.com ”上線即掀起了不小的浪頭,上線第一周,0 投放達到 100 萬用戶周活,登上國內第七大搜索引擎的位置,連開發團隊 Peak Labs 都未曾預料它會如此火爆。

關于活躍粉絲,新浪和DT財經互掐了一把
DT 數說最近做了一項有關明星粉絲的數據報道,重點分析了粉絲超千萬的全部 317 位明星以及入選微博超話榜的流量擔當們,利用微博推廣功能提供的“可投粉絲”來指代活躍粉絲,計算活躍粉絲占比來評估明星微博粉絲的含水量,探究哪些明星的微博粉絲含水量高,含水量高低有什么規律,并根據粉絲數和活粉率把超話榜明星分成了四大象限:高粉絲數低活粉率、高粉絲數高活粉率、低粉絲數高活粉率、低粉絲數低活粉率。
之后,“新浪微營銷” 發布聲明質疑文章中“用‘可投粉絲’來指代活躍粉絲”的統計方式并未與官方核實,缺乏事實依據,由此推算出的“活躍粉絲占比”、“含水量”等數據嚴重失實,給公眾帶來了誤導。??

相關鏈接:317位頂級明星PK,誰的微博粉絲注水最嚴重?
新浪微營銷相關聲明
山西人最喜歡追星?從數據看明星粉絲的地域構成:https://zhuanlan.zhihu.com/p/58661739
誰是最復雜的小說
一個波蘭物理學家團隊在 2016 年的《Information Sciences》雜志上,發表了一篇名為《量化敘事文本中長期關聯的來源和特征》的論文。他們選取了世界范圍內的一百多部文學作品進行了文本復雜度分析,探究在敘事文本中是否可以找到有效的與復雜度相關的度量指標,可以用來評判一部敘事文本的優劣程度。研究者們提取了兩個指標作為評判一部作品敘事復雜度標準:長程相關性與多重分形復雜度。發現最復雜的小說是著名意識流作家喬伊斯的《芬尼根的守夜靈》 。不過小編表示,和這篇論文相比,這些小說也不算復雜了…… 后附一篇論文的中文摘要,邀請大家一起來燒腦。

中文摘要:誰是最“復雜”的小說:文學敘事中的長程關聯與多重分形
活動
—
聯合國世界數據論壇征稿啟動
第三屆聯合國世界數據論壇將于 2020 年 10 月 18 日至 10 月 21 日由瑞士聯邦統計局主辦。聯合國世界數據論壇旨在加強各團體(如信息技術,地理空間信息管理者,數據科學家和用戶以及民間社會組織)之間的合作。本屆論壇旨在舉辦會議,討論如何采用創新的數據和統計方法以解決公眾關心的問題。這又將是一個大神云集的論壇,也是一個了解交流世界數據前沿動向的好機會。日前,論壇的征稿活動啟動,投稿開放時間為 2019 年 12 月 2 日到 2020 年 1 月 31 日。

https://unstats.un.org/unsd/undataforum/call-for-session-proposals-for-united-nations-world-data-forum-2020/
CREDIT
—
爆料人:@ Ingrid @ 包小包 @ 服老思
編輯:@ 包小包
排版:@ 包小包
就是這個人還沒點在看
原標題:《全世界網友如何表達“笑”》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

