- +1
從一到無窮大:大語言模型對受訪者樣本的模擬
編者薦語:
本文的創新之處在于從大語言模型的原理入手,證明通過合適的訓練(conditioning)即可以大致消除語言模型的偏見來較準確地模擬特定人群的反應。作者將模擬的準確性定義為“算法保真度”,并且設置4條標準來檢驗GPT-3是否足夠準確。本文證明,在美國大選方面GPT-3可以大致準確模擬各個人群的反應。本文展現了大語言模型在政治學及社科研究方面的潛力,例如可以低成本和較準確地對某一特定對象進行模擬實驗或調查。值得注意的是,本文中模型的“算法保真度”局限于在美國大選及美國公共政治觀點。在其他國家和地區研究方面,模型生成回復和人類回復可能存在偏差,需要進一步研究。
大語言模型對受訪者樣本的模擬
摘要:
人工智能的應用有時會受到模型內的偏見(如種族主義)的限制,這些偏見通常被視為模型的統一屬性。本研究表明,GPT-3 語言模型中的偏見是細粒度(fine-grained)的,且與人口統計學相關。這意味著適當的訓練可以使它較為準確地模擬各人類子群體的反應分布。本文將這一特性稱為“算法保真度”,并探索其在 GPT-3 中的應用范圍。作者以數千名真實人類參與者的社會人口背景故事為條件,創建了 “硅基樣本”,然后對硅基樣本和人類樣本進行比較,以證明 GPT-3 中的信息與人類的信息遠不僅僅是表面相似,而是反映了人類思想、態度和社會文化背景之間復雜的相互作用,而這正是人類對于事情的態度特征。因此具有算法保真度的語言模型是一種強大的工具,可促進各學科對人類和社會的理解。
作者簡介:
Lisa P. Argyle
Ethan C. Busby
Nancy Fulda
Joshua Gubler
Christopher Rytting
David Wingate
編譯來源:
Argyle, L. P., Busby, E. C., Fulda, N., Gubler, J. R., Rytting, C., & Wingate, D. (2023). Out of one, many: Using language models to simulate human samples. Political Analysis 31(3), 337-351.

本文作者之一 Nancy Fulda
一、導言
近年來,機器學習工具極大推動了社會科學研究的發展。然而像GPT-3 這樣的大語言模型在增強對人類社會和政治行為的理解方面的潛力卻在很大程度上被忽視了。因此,作者認為這些模型有潛力在各種社會科學研究中部分替代人類受訪者的角色。
人工智能模型傾向于保留其創造者有關種族、性別、經濟和其他方面的偏見,而大多數相關討論都將其視為模型的單一、宏觀的特征。作者認為,最好將其理解為對人類思想、態度和語境之間關聯模式的反映。作者研究表明,同一語言模型在經過適當訓練后,產生的“偏見”(bias)既可以傾向于(to)也可以反對(against)特定群體和觀點的輸出結果,這些輸出結果與在擁有一定特征的人所擁有的反應模式非常吻合。通過對具有目標身份和個性特征的模擬 “個體 ”進行“訓練”(conditioning,指對模型進行輸入從而得到希望的輸出,可以理解為條件反射),可以在模型中從多樣且經常不相連的反應分布中進行選擇,而每種反應分布都與真實的人類子群體密切相關。作者將模型能夠準確反映這些分布的程度稱為“算法保真度” (algorithmic fidelity)。
語言模型的“算法保真度”對其在社會科學中的應用至關重要,因為它使研究人員能從一個語言模型中深入了解許多群體以及這些群體組合的不同態度和觀念模式。在三項研究中,通過根據美國的多個大型調查中的受訪者的特征對GPT-3進行訓練,從而獲得GPT-3符合“算法保真度”標準的證據。這些調查包括美國全國選舉研究(American National Election Studies, ANES),以及Rothschild等人的 “隨意分類的黨徒”(Pigeonholing Partisans)數據。通過對模型進行訓練,在3組研究中為每個人類研究參與者生成一個AI模擬的 “硅基人”(Silicon Subject)(指使用語言模型訓練生成的虛擬受訪者),然后要求這些虛擬受訪者完成與人類受訪者相同的任務。為了評估算法的保真度,作者討論了“硅基人”中思想,態度和情境之間的復雜關系模式在多大程度上反映了人類群體中的該關系。
在研究1中,作者要求GPT-3 “硅基人”列出描述符合美國兩黨黨員的詞,并展示這些詞和對應的人類列出的詞的密切程度。研究2和研究3中,作者探討了各種人口統計數據、態度和報告行為之間的關系;結果表明,GPT-3生成的“硅基人”與人類一樣存在類似的思想、態度和情境之間互動的關系模式。因此,在美國政治領域,研究人員可以使用 GPT-3進行“硅抽樣法”(Silicon Sampling)(指使用語言模型訓練生成大量虛擬受訪者用于測試)來探索研究假設,然后再以人類為研究對象進行研究。
二、GPT-3模型原理
形式上,像 GPT-3 這樣的語言模型是標記(“Token”,指用于表示文本或語音等數據的最小語義單位。例如在自然語言處理中,token可以是一個單詞、標點符號或短語 )的條件概率分布 p(x|x1,…,xn-1),其中每個xi來自一個固定的詞匯表。通過從該分布中迭代采樣,語言模型可以生成任意長的文本序列。然而,在生成文本之前,像 GPT-3 這樣的語言模型需要進行訓練,即必須向其提供由 {x1,…,xn-1} 組成的初始輸入標記。作者將這種訓練文本稱為模型的語境(“context”)。例如在上下文 {x1, x2, x3} = “Can you come”中,語言模型可能賦予x4 = “home”高概率,而賦予x4 = “bananas”低概率,但將上下文中的一個單詞改為 {x1, x2, x3} = “Can you eat”,情況就會相反。在每一個生成步驟中,模型都會估算出一個概率分布,該概率分布對應的概率是:假如模型在閱讀預先寫好的文本,那么詞匯表中的任何給定標記成為下個觀察到的xi的概率。利用分布函數,它可以從最有可能的候選詞中選擇一個,新的xi被添加到訓練用的語境(conditioning context)中,整個過程重復進行。這一過程一直持續到生成預指定數量的標記,或外部介入停止進程為止。
三、算法保真度
作者將算法保真度定義為模型中思想、態度和社會文化背景之間的復雜關系模式在多大程度上準確反映了人類子群體中對應的關系模式。這個概念的核心假設是:模型生成的文本不是從單一的總體概率分布中挑選出來的,而是從多種分布的組合中挑選出來的。作者認為語言模型的高水平、與人類類似的輸出,是基于模型與人類類似的思維上的基本概念的互相關聯。這意味著,給定基本人類人口背景信息后,模型會顯示出概念、觀點和態度之間的潛在關聯模式(pattern),這些模式與具有匹配背景的人類記錄的模式如出一轍。因此語言模型至少必須提供符合以下四項標準的,重復,且有一致性的證據來證明其擁有算法保真度:
標準1(社會科學圖靈測試 Social Science Turing Test):模型生成的回復與平行的人類文本無法被人類有效區分。
標準2(后向連續性 Backward Continuity):模型生成的回復與其輸入/“訓練用的語境”中的態度和社會-人口統計信息(socio-demographic information)相稱,使得查看回復的人類能夠反推出輸入的這些要素。
標準3(前向連續性 Forward Continuity):生成的回復是從所提供的“訓練用的情境”中自然產生,可靠地反映了這個情境的形式、語氣和內容。
標準4(模式對應性 Pattern Correspondence):生成的回復反映了可在人類生成的類似數據中觀察到的思想、人口統計信息和行為之間的潛在關系模式。
作者沒有提出具體的指標或數字閾值來量化這些標準,因為適當的統計數據將取決于不同的數據結構和學科標準。作者認為,最好的衡量標準是在多個數據源、不同衡量標準和多個群體中都反復符合每項算法保真度的標準。
四、硅抽樣法
將語言模型應用于社會科學研究會產生一個的問題:互聯網用戶的人口統計特征(模型在此基礎上進行訓練)既不能代表大多數相關人群,也不具有人口統計學上的均衡性,而且語言模型是在固定時間點獲取的互聯網快照(Snapshot)上進行訓練的。
作者提出了一種稱為硅抽樣法(Silicon Sampling)的方法,可以糾正語言模型邊際統計的偏斜(skewness)。GPT-3將投票模式V和人口統計信息BGPT3 共同建模為 P(V, BGPT3) = P(V|BGPT3)P(BGPT3)。然而,在大多數社會科學家感興趣的人群中(例如,在所有有投票資格的公民中),背景故事P (BGPT3) 的分布與P(BTrue) 的分布并不匹配;如果不進行修正,則P(BTrue) 的分布與 P(BGPT3) 的分布不同,關于邊際投票模式的結論P(V) = ∫B P (V|BGPT3)會發生偏斜。
為了克服這一問題,作者利用語言模型的條件性質,從已知的、具有全國代表性的樣本(例如 ANES)中抽取背景故事,然后根據 ANES 抽樣的背景故事估計P(V)。這樣就可以計算P(V|BANES)P(BANES)。只要能夠很好地模擬條件分布P(V|B),就可以研究任何指定人群的模式。由于從GPT-3的文本成分分布中取樣的能力本身不能保證這些分布忠實反映特定人類子群體的行為。為此研究者必須首先檢查該模型在研究領域和相關人口群體方面的算法保真度。
五、研究
a) 研究1
對 GPT-3 算法保真度的首次檢驗涉及對Rothschild等人的 “隨意分類的黨徒”(Pigeonholing Partisans)數據。這項調查要求受訪者列出四個詞來描述共和黨人和民主黨人。Rothschild 等人發現,人們談論黨派人士的方式各不相同,主要集中在特質、政治問題、社會群體或三者的結合上。此外,人們在談論自己的政黨時往往比談論其他政黨更積極。在本研究中,作者運用硅抽樣法,詢問 GPT-3 能否生成與人類生成詞語難以區分的關于美國黨派黨員的文本。為此作者為 “隨意分類的黨徒”調查中的每個人類受試者構建第一人稱背景故事,生成“硅基人”,如圖1所示。利用這些文本,作者要求GPT-3對新詞進行采樣。由于訓練用的語境的設置,GPT-3幾乎總是以整齊劃一的四組單詞作為回應,不過與人類一樣,它偶爾也會以長短句、短文或無回應作為回應。使用正則表達式對生成內容進行處理后,作者從每個樣本中提取出最終的數據集。

圖1: 研究 1 中4個硅基人的語境(context)和文本補全(completion)的例子。文本表示訓練用的語境;下劃線詞表示插入模板的人口統計信息;藍色單詞是四個最終生成的單詞。
圖2按數據來源(GPT-3 或人類的回復)和反應來源的意識形態(民主黨還是共和黨)比較了數據集中描述民主黨人和共和黨人最常用的詞語。氣泡大小代表詞語出現的相對頻率;列代表調查回復作者的意識形態。定性的角度上,人類和GPT-3列出的(描述兩黨黨員的)詞匯最初都符合政治學學者的預期。例如GPT-3 和人類都使用一組常用詞來描述民主黨人,而很少使用這些詞來描述共和黨人。
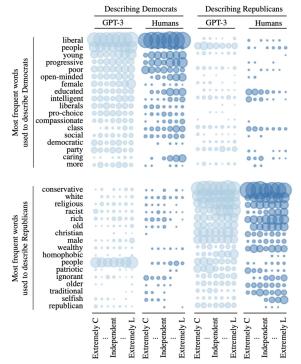
圖2: 原始的“隨意分類的黨徒”數據集和相應的GPT-3生成詞。氣泡大小代表詞語出現的相對頻率;列代表名單撰寫者的意識形態。GPT-3 使用的詞與人類相似。
為了對這些數據進行正式分析,作者通過調查平臺Lucid雇傭2873人對人類和GPT-3作為調查受訪者生成的7675篇調查的回復進行評估,但沒有說明哪個回復來源于人還是GPT-3。每個人評估8個隨機分配的回復,每個回復同時由3個不同的人評估。
作者向這些評估者展示了4個單詞的調查回復,并作了如下前言:“考慮以下對(共和黨/民主黨)的描述:”。然后要求他們回答6個問題。首先,作者要求他們猜測調查回復者的黨派(共和黨、民主黨或獨立黨派)。然后,作者要求他們從 5 個方面對名單進行評分:(1)正面或負面語氣,(2)(回復的)整體極端性,以及回復是否提及(3)特質、(4)政策問題或(5)社會團體。然后受試者依次觀看另外8份隨機選取的調查回復,并被告知其中一些回復是由計算機模型生成的,受試者被要求猜測每份清單是由人類還是計算機生成的。
通過這種設計,作者探索了圖靈測試的兩種社會科學變體:(1)人類評估者是否能識別人類和GPT-3生成的調查回復之間的區別;(2)人類是否認為兩種來源的調查回復內容相似。這些測試涉及標準1(社會科學圖靈測試 Social Science Turing Test)和標準2(后向連續性 Backward Continuity)。
作者發現了支持這兩種標準的證據:人類參與者猜測61.7%的人類生成的調查回復是人類生成的,而61.2%的 GPT-3 調查回復被認為是人類生成的(雙尾差異(two- tailed difference)p = 0.44)。雖然要求參與者判斷一份調查回復是由人類還是計算機生成的,會導致他們猜測一些調查回復并非來自人類,但這一趨勢并不因調查回復來源的不同而變化。
考慮到第二項探索的結果:參與者是否注意到人類和GPT-3生成的調查回復在特征上存在差異,這一點尤其有趣。為了確定這些差異,作者使用普通最小二乘法(OLS)估計了回歸模型,將評價名單的5個特征(積極性、極端性以及對特質、問題和群體的提及)分別與二分來源變量(0 = 人類,1 = GPT-3)和一系列控制變量(記錄了 Rothschild 等人數據中原始名單撰寫者的性別、種族、收入、年齡和黨派身份)進行回歸。所有模型都包括評估者的固定效應(因為每個評估者評估了8份名單),以及評估者和名單的聚類標準誤差(因為每份名單評估了3次)。
圖3(B) 顯示了所有調查回復(人類和GPT-3)中被評估為具有各種特征的預測百分比。結果表明人類和 GPT-3 生成的調查回復在內容和語氣方面的評價具有顯著一致性。例如,人類調查回復撰寫者包含的個性特征(如 “偏執”、“道德”)多于其他成分(72.3%的調查回復)。GPT-3也是如此(調查回復中的66.5%)。在人類和 GPT-3 生成的調查回復中,不到一半的調查回復被評為極端調查回復(分別為39.8%和41.0%)。這種相似性體現在所有5個特征,除一個特征外,其他特征都徘徊在50%左右。唯一的例外是 “特質”,它在人類和GPT-3數據中的頻率都要高得多。這與人類的調查回復的原始模式吻合。GPT-3反映了這一例外情況以及所有其他特征的模式,這有力地證明了它所包含的算法保真度的深度。
此外,如圖3(A)所示,當深入到更詳細的層次來探索這些結果背后的基本模式時,GPT-3在這個層次上也反映了與人類相似的模式(標準4,模式對應性)。人類和GPT-3在使用正面和極端詞匯方面的相似性顯著,可以從名單作者的意識形態分組中看出。
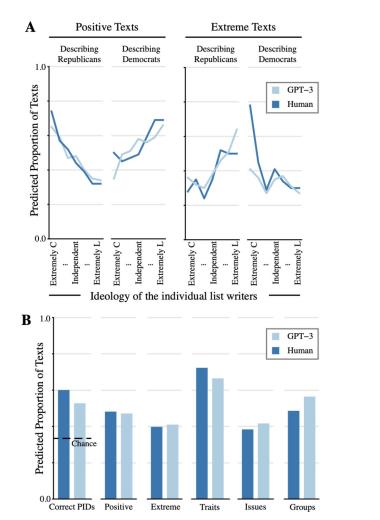
圖3:對于Lucid調查的人類/GPT-3的回復的分析圖
以上分析可以證明:1. 人類評估者無法正確區分人類與GPT-3生成的調查回復;2. 他們對這些調查回復的內容/特征的評估非常相似。為了探討參與者在多大程度上能夠利用這些列表來正確猜測列表作者的真實黨派傾向,作者估算了一個與剛才類似的模型,將一個二分變量(1 = 是;0 = 否)與調查回復來源(GPT-3與人類)和相同的對照組進行回歸,以確定參與者是否正確猜測名單作者的黨派(1 = 是;0 = 否)。圖3(B)最左側的條形圖顯示了根據來源類型預測的正確率。
參與者在看到來自兩種來源的調查回復時,猜測其作者黨派的正確率明顯高于隨機選擇的概率(33%,因為受試者可以猜測共和黨、民主黨或獨立黨派),為 GPT-3算法保真度提供有力證據。看到人類生成的調查回復的受試者比看到GPT-3 列表的受試者成功猜測的頻率高出約7.3%(60.1% vs. 52.8%),這一差異統計學顯著(雙尾檢驗 p < 0.001)。人和 GPT-3 的文本都包含了猜測創建者黨派傾向所需的明顯的情感線索。
研究1結果表明,GPT-3的算法保真度非常高:標準1(社會科學圖靈測試)和標準2(后向連續性)得到了反復、一致的支持,標準4(模式對應性)也有一些初步證據。在這些案例中,作者均觀察到這些標準在不同的測量方法和不同的美國人口子群體中都得到了支持。
b) 研究2
研究 2 中,作者使用了 2012 年、2016 年和 2020 年的ANES(美國全國選舉研究)作為數據來源。首先需要考慮根據 2012、2016 和 2020 年 ANES 參與者的人口統計學特征構建的 GPT-3 硅基樣本(Silicon Sample)所報告的投票選擇分布與其匹配的人類樣本的相似度。該研究就要求 GPT-3 從有限的選項中生成投票選擇(如在2016年投票給特朗普),且必須根據提供的人類背景以不同的方式生成選擇。因此,這個研究評估了標準 3(前向連續性)和標準 4(模式對應性)。研究 2 還探索了 GPT-3 的時間限制可能帶來的影響:該模型的訓練語料庫來源不晚于2019年,因此2020年的數據使作者能夠探索語言模型的算法保真度在原始訓練語料庫所處時間之外的時間內會如何變化。
作者使用以下ANES變量作為GPT-3的訓練條件:(1) 種族/民族自我認同,(2) 性別,(3) 年齡,(4) 保守-自由意識形態自我定位,(5) 黨派認同,(6) 政治興趣,(7) 教堂出席率,(8) 受訪者是否報告與家人和朋友討論政治,(9) 與美國國旗相關的愛國主義情感,以及 (10) 居住州(注:(9)與(10)分析時無2020年的數據)。作者記錄了GPT-3經過背景故事訓練后,填寫共和黨/民主黨候選人,以補充完整 “在[年份],我投票給了...... ”這句話的概率。在 GPT-3 中使用這些ANES變量作為訓練用文本,可以讓作者比較 GPT-3 硅樣本多大程度上復刻(replicate)人類樣本中每個變量與投票選擇間的關系。接下來受訪者/GPT-3 表示在該次選舉中投票給共和黨候選人時,投票選擇編碼為1,而投票給民主黨候選人時編碼為 0。為了使 GPT-3 的預測結果與觀察到的人類數據相匹配,將概率預測值二分(dichotomize)為 0.50,數值高則表示投票給共和黨候選人。
可以觀察到GPT-3和ANES受訪者報告的兩黨總統投票選擇比例高度吻合。在整個樣本中平均計算,GPT-3 報告的 2012 年投票給羅姆尼的概率為 0.391;而 ANES 的百分比為 0.404。在 2016 年的數據中,GPT-3 投票給特朗普的概率為 0.432,而 2016 年 ANES 的概率為 0.477。2020 年,GPT-3 投票給特朗普的概率為 0.472,而來自 ANES 的百分比為 0.412。在這三種情況下,作者都可以看到 GPT-3 存在輕微總體偏差。然而,ANES 和 GPT-3 估計值之間的實質性差異相對較小,與作者算法保真度和修正偏斜邊際值的論點相一致,無法排除 GPT-3 的反應與美國人口中的子群體反應之間存在顯著的相關性。
表1中的統計數據報告了ANES的自我投票報告與GPT-3的二進制投票報告之間的兩種形式的相關性。對GPT-3的投票概率進行二分法處理以匹配人為測量指標(ANES)。在所有三年的調查數據中, GPT-3和人類受訪者之間存在顯著的對應關系。2012年所有受訪者的四分相關性(Tetrachoric Correlation)為 0.9,2016年的估計值為 0.92,2020年的值為 0.94。考慮到各年背景的不同,這種持續的高相關性非常顯著。
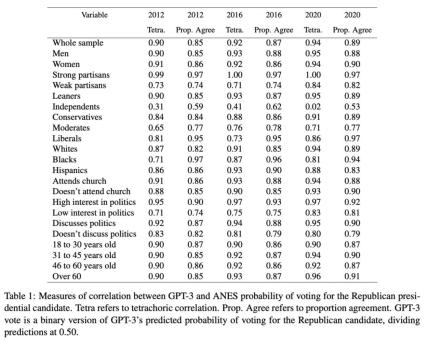
表1: GPT-3 與 ANES 對共和黨總統候選人投票概率的相關性測量。Tetra 指四分相關性(Tetrachoric Correlation)。Prop. Agree指比例一致性(Proportion Agreement)。GPT-3 vote指 GPT-3 預測的投票給共和黨候選人概率的二進制版本(將預測值除以 0.50)。
這種模式對應性同樣出現在美國人口各子群體中。從2012,2016和2020年這3年的ANES報告的人類投票比例和對應的GPT-3投票比例中可以發現,超過一半的各個人類子群體對應的四項相關性大于等于 0.90。表1的比例一致性還顯示,2012、2016和2020年的兩份選票選擇報告之間的原始一致性很高。這一總體模式只有“獨立候選人”一個例外。然而,這也是表1中唯一偏離整體趨勢的地方。現有的政治科學研究表明,這部分人尤其難以預測,因為他們對兩黨選擇的矛盾最大,最不可能投票,政治知識最少,對政治最不感興趣。因此,總的來說,表1中的結果為算法保真度提供了有力的額外證據,標準3(前向連續性)和標準4(模式對應性)得到了反復一致的支持。
c) 研究3
研究 3 考察了GPT-3復刻各種概念之間復雜關聯模式的能力。鑒于這項任務的復雜性,作者僅針對2016年的 ANES 數據進行了研究:在研究 2 投票預測的基礎上,作者擴大了要求GPT-3生成的信息輸出的規模,并使用由此產生的數據來評估復雜的概念間相關性(即標準4(模式對應性))。
這項研究的挑戰在于,在詢問特定選舉中的投票選擇時(即 “特朗普”與 “希拉里”),可能的回答自然是有限個,但現在并不存在這樣的回答,因此作者開發了一種方法,使 GPT-3 經過訓練后能夠從一系列選項中提供特定的回答。為此作者制作了一個訪談式的條件模板。這種方法有兩個目的。首先,利用語言模型的零樣本學習(zero-shot learning,指模型經訓練可對對象或概念進行識別和分類,而事先不知道這些類別或概念的任何示例)特性,(訓練用文本的格式)會引導 GPT-3 使用從“采訪者”提供的選項中抽取的標記串(strings of tokens)回答調查問題。其次,訓練用文本中的問題提供了必要的人口統計和態度背景信息,以生成不同的硅基人。研究使用人類在2016年ANES調查中對11個調查問題的回答生成條件文本,然后使用 GPT-3 預測對第12個問題的回答。
通過使用 ANES 和硅基人的數據,計算ANES樣本(“人類”)中每個調查項目組合的Cramer's V值,以及 ANES 訓練值和由此產生的 GPT-3 回復(“GPT-3”)之間的Cramer’s V值(Cramer's V值提供了一個概括性的關聯度的度量,可以解釋原始數據中基準數值得的變化情況)。圖4顯示了兩個數據源之間Cramer’s V值的比較。人類的調查數據中的關聯模式與GPT-3生成的調查數據中的關聯模式之間具有顯著的對應性(Cramer’s V值之間的平均差異為0.026)。可以看出,GPT-3 生成的回復的 Cramer’s V值并不是一致的高或低,而是反映了人類數據中存在的較強或較弱的關系。在人類數據中關聯性不強的兩個概念,在GPT-3數據中的關聯性同樣不強,反之亦然。在圖4中,雖然GPT-3中的關系模式與ANES中的關系模式在精確程度上存在差異,但在絕大多數情況下,GPT-3與ANES之間的對應關系之顯著令人驚嘆。
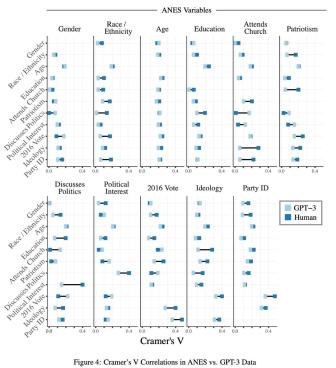
圖4:ANES數據與GPT-3數據之間的Cramer’s V相關性(Cramer’s V Correlations)
作者根據特定的人類調查資料提供了第一人稱背景故事,硅基樣本的值與人類在個體層面上的反應不太可能完全一致。對于每個文本補全(text completion),語言模型都會使用隨機抽樣過程,從可能的下一個標記的分布(distribution of probable next tokens)中選擇文本來補全。因此,只要樣本量足夠大就能預期硅基樣本中文本回答的總體分布與人類數據的總體分布吻合。此外,與所有隨機過程一樣,預計硅基樣本的不同抽樣也會產生一些變化。
這些結果再次為標準4(模式對應性)提供了令人信服的、一致的重復證據。GPT-3 重現了細微的關聯模式。在提供真實調查數據作為輸入時,GPT-3能可靠地回答封閉式(closed-ended)調查問題,其方式與人類受訪者的回答非常相似。(人類與GPT-3)統計上的相似性延伸到個人行為、人口統計特征和復雜態度等測量指標之間的一整套相互關系。因此作者再次將此研究結果視為算法保真度的有力證據。
六、大語言模型的前景
目前為止的重點是通過將GPT-3的輸出結果與人類數據比較,來證明其算法保真度。本文的證據表明算法保真度是GPT-3等工具的一個重要屬性,因為它證明了這些語言模型可以在人類數據之前或沒有人類數據的情況下使用。
研究 1 中硅基樣本的數據表明:(1) 人們用不同的詞語來描述共和黨人和民主黨人,這些詞語突出了對這兩個群體的不同刻板印象;(2) 這些文本的情感內容和極端性與個人的政治信仰和身份系統地聯系在一起;(3) 對黨派成員的刻板印象包含基于問題、群體和特質的內容;(4) 其他人可以根據他們對民主黨人和共和黨人的刻板印象來猜測個人的黨派傾向。僅使用 GPT-3 中的數據,所有這些都是顯而易見的。有了這些信息,有興趣的研究人員就可以用廉價的GPT-3模型而不是人類數據收集設計調查問題、實驗處理方法和代碼手冊來指導人類研究。
研究2和研究3也是如此。研究2的消融分析(Ablation Analysis)表明,研究人員若想準確了解美國人的投票行為,應在輿論研究中納入哪些變量。根據GPT-3 的結果,社會科學家可以設計一項實驗或觀察研究,以嚴謹和因果的方式確認和剖析這種關系。研究結果還表明,哪些變量具有潛在的混雜因素,應將其納入回歸和其他具有因果關系的計量經濟學模型的預分析計劃中。即使學者只能訪問GPT-3而尚無人類基線,所有這些見解對于他們都是可能獲取的。在針對特定主題/領域的特定模型中建立算法保真度后,研究人員可以利用從硅基樣本中獲得的洞察來試驗不同的問題措辭、分揀不同類型的測量指標、識別需要更仔細評估的關鍵關系,并在收集人類參與者的任何數據之前制定分析計劃。
編譯 | 鄭嘉雋
審核 | 楊濤
終審 | 李晶晶
?Political理論志
本文內容僅供參考,不代表Political理論志觀點

前沿追蹤/理論方法/專家評論
ID: ThePoliticalReview
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2024 上海東方報業有限公司

