- +1
歷史與AI的距離:聊天機器人在歷史學科科研中的應用
2022年11月30日,OpenAI公司的聊天機器人ChatGPT上線。半個月之后,就有在美國大學教書的友人說起ChatGPT引發了自己對工作的焦慮。2023年9月,《美國歷史評論》專門探討21世紀歷史研究新實踐的欄目的“歷史實驗室”(History Lab)發表了一組題為《人工智能和歷史實踐》的圓桌論文,及時回應了美國同行對人工智能是什么以及能如何與歷史學進行互動的疑問。七篇文章關聯到了對歷史學研究者來說相對更熟悉的議題,比如“數字史學”,更多的則是一些相對新的名詞,比如“深度學習”“噪聲效應”等等。
中文媒體對人工智能的興趣在2023年達到一個新高度。高等院校同樣如此。例如,2023年12月28日,美國羅文大學杰出教授王晴佳受復旦大學西方史學史團隊邀請作了題為《數字化、人工智能和歷史學的未來》的講座,全面而深入地講述了人工智能對歷史研究的影響,讓筆者深受啟發。
在剛剛過去的龍年春節期間,OpenAI發布的文本到視頻轉換模型Sora展現的樣片又引發了一輪激烈的討論。無論用戶的要求是刻畫當代時尚女性行走在東京商業區的情景,還是模擬淘金熱期間的加利福尼亞州的樣貌,Sora都能較為準確乃至栩栩如生地實現。OpenAI甚至聲稱Sora能夠理解用戶輸入的內容在物理世界中的存在方式,這使得以往的AI視頻生成工具相形見絀。

與此同時,谷歌在大模型信息處理能力的賽道持續發力,推出了Gemini 1.5 Pro。據稱它可以處理高達100萬個tokens的上下文窗口,差不多對應一小時的視頻、11小時的音頻、超過30,000行代碼的代碼庫或超過700,000字的文本(約等于《伊利亞特》和《奧德賽》的文本量相加再翻一倍)。這些革新體現出人工智能(Artificial Intelligence)的計算能力在不斷以驚人的速度提升。《經濟學人》雜志在2023年2月初刊載了《人工智能的繁榮:歷史的經驗》一文,將GPT的出現和亨利·福特的企業開始使用流水線生產汽車相提并論。易言之,人工智能的繁榮將不僅僅是信息技術領域快速發展的標志。由此而生的新技術、新產品和新服務很快會滲透到人類生活的許多角落,進而催生人類社會的變化。
你與AI的距離:很近又很遠
對于身處高校的學者和學生而言,AI大模型及相關產品快速迭代帶來了許多視覺和心理上的沖擊。在應用層面上,對于數據科學(Data Science)的研究者和依賴電腦進行大數據分析的研究者(包括數字人文的研究者)來說,早已熟稔ChatGPT,大模型、機器學習之類的概念,各種分析工具和代碼工具已融入自己核心的工作流,創造出擁有極佳視覺效果的學術成果。不過,更多的師生是利用聊天機器人來處理郵件措辭、文章改寫、日常報告生成等重復性強的瑣事。“藝高人膽大”的“新科技愛好者”則可能在過去一年里體會到了大語言模型的“致幻術”,如從機器人那里獲得了“西南聯大的重要創始人之一楊開慧成功參加了位于蘇黎世的第七屆國際數學家大會并獲得了惟一的一枚銅牌”這樣的“新知”,著實為痛苦的期末周送來了富有新意的笑料,強化了人工智能聊天機器人仍是“人工智障”的刻板印象。
從學術研究的角度來看,有鑒于中文歷史學期刊的論文發表周期動輒以年計算,且仍有許多刊物無法給文章配圖,要針對正在迅速發展的、媒體形式極為多樣的人工智能展開討論存在相當大的困難。英文的歷史學期刊則在ChatGPT面世后不久,便開始傳遞不同領域學者的洞見。例如,《歷史與理論》雜志在2022年12月出版了《數字歷史和理論》專刊。其中收錄的10篇專論針對人工智能時代下的歷史學與歷史敘事等宏觀主題展開辯論,關注焦點則是史學理論層面的思考。
其中馬尼·休斯-沃林頓(Marnie Hughes-Warrington)在有關數字歷史和理論的專刊上發表的《走向對人工歷史創造者的認可》已經提到了AI在歷史編纂學中的潛力。他認為,人工智能的歷史學應用不僅局限于模仿人類的歷史敘事,而是通過結合推理和普遍接受的觀點,形成了一種新的歷史敘事方式。沃爾夫·坎斯泰納(Wulf Kansteiner)則在《歷史學家的數字興奮劑:歷史、記憶和歷史理論能否人工智能化?》一文中指出,雖然GPT生成的文本無法保證結構上的真實,但史學理論家可以讓定制的大型語言模型編寫一系列關于相同事件的描述性、敘事性和論證性歷史,從而探究描述、敘述和論證在歷史寫作中的精確關系。


上述學者的討論固然在理論層面頗有建樹,但鮮少涉及大型語言模型產品的具體使用方法和技巧。為數不多的例外是美國林登伍德大學(Lindenwood University)的學者團隊在2023年年底在《元宇宙》(Metaverse)上發表的論文《數字歷史人物復活:以瑪麗·西布莉為例的定制ChatGPT案例研究》。該文以林登伍德大學的創始人瑪麗·西布莉(Mary Sibley)為實驗對象,將她的海量日記內容作為Claude 2.0的訓練數據,開發出一個能夠復現西布莉獨特語調和觀點的聊天機器人,類似于2019年熱播日劇《輪到你了》第二季中的AI女主角。這一成果展現了一種新穎的歷史研究和互動學習方式,也為學界如何利用數字技術復現擁有海量史料的歷史人物提供了啟發。
實際上,當下大語言模型產品的能力已經足夠成為高校師生日常課程學習和科研工作的助手,在信息檢索、文獻閱讀、筆記管理乃至科研創新等事務中發揮關鍵作用。尤其對于全球史的研究者來說,常常需要處理大量涵蓋了不同地區、國家和文明間的相互聯系與比較的材料和文獻。運用AI產品來提高信息檢索效率和處理能力,有助于更深入地探索和分析這些復雜的歷史關系,來提高研究的深度和質量。然而問題在于,如何將AI產品整合到自己的學習或工作流程之中,優化或定制自己的專屬機器人,為其增添功能,提升自己的輸入和輸出效率,也就是利用人工智能來自我賦能,從而更高效地處理龐雜的信息。
絕知此事要躬行:管窺國內大模型產品工具箱
目前大部分人使用大語言模型產品的方式是直接以自然語言輸入自己的問題到對話框,并等待AI的回復,仿佛在與一位真人助手交談。這簡單的過程中其實蘊含著很多值得學習的工具性知識。在互動中,AI回復的質量與大模型自身能力密切相關,也受到用戶發出的提示詞(Prompt)內容的重要影響。固然,目前網絡上已經存在許多詳細的提示詞指南,但一份理想的提示詞是需要用戶自己在反復實踐的互動中不斷地錘煉出來的,這就要求用戶所處的網絡社區中有AI產品滿足以下需求:易獲得、模型性能好,且有充足社區資源提供指導。
除了前文提到的ChatGPT和Gemini Pro這兩個大模型領域的“當紅流量小花”,國內也有不少相當優秀的同類產品可供使用。比如月之暗面科技推出的智能聊天機器人(Chat bot)Kimi Chat就有驚艷的長文本處理能力,能夠支持長達20萬漢字的輸入。又如清華系創業公司的智譜AI。用戶可以在智譜清言的客戶端體驗GLM-4支持的“長文檔解讀”“高級聯網”“數據分析”“AI畫圖”等多樣化功能。尤其,這一開放平臺目前向實名認證的新用戶免費贈送數百萬tokens,對想要進一步探索AI世界的新手十分友好。字節跳動推出的智能體創建平臺“扣子”(Coze)同樣頗受好評,原因在于能讓缺乏編程經驗的“小白”快速上手制作自己專屬的聊天機器人,并利用知識庫(Knowledge),插件(Plug-in),工作流(Workflow)等功能增強機器人的性能。
當然,選擇哪款大語言模型產品最終取決于個人的需求或偏好。用戶如何通過持續的使用和探索,找到能夠融入自身現有工作流的工具,從而有效提升學習和工作效率才是關鍵。接下來我將以學習第一次世界大戰的歷史為應用情境,利用Kimi Chat、智譜AI開放平臺、“扣子”來簡單展示如何使用提示詞優化(Prompt Optimization)、知識庫、插件來提升模型的回答質量,使之成為歷史學的學習與科研助手。
四兩撥千斤:人工智能助手的快速優化策略
聊天機器人的回答質量受到模型的數據集和參數影響,目前,許多從事垂直領域大模型開發的研究者積極應用微調(fine-tuning)技術來訓練大語言模型,使之在特定領域有更好的表現。但大部分非計算機專業的師生并不具備微調所需的算力資源和專業知識,掌握這一技術的時間成本也足以令人望而卻步。但是,在不改變模型的前提下,從用戶開始琢磨自己想問什么,到聊天機器人最終給出回復,中間有許多步驟提供了可優化的空間(如下面的流程圖所示的A和D),來盡可能地使機器人的回復貼合用戶所期待的答案。換言之,在人機互動中,大語言模型聊天機器人通過其預訓練能力理解用戶輸入,并可能結合實時檢索來響應查詢。用戶可以做的,則是向機器人更明確表述自己的需求,“教”機器人如何提取某些信息,這往往可以通過系統的“提示詞工程”(Prompt Engineering)來實現。而提供知識庫或插件,則是為機器人在最終生成回復之前提供額外的信息支持,市面上大部分大語言模型產品已為缺乏編程和機器學習基礎的用戶提供了此類服務,相信大家可以花費較短的學習時間來掌握相關應用。

以下是三個與第一次世界大戰史有關的研究情境中如何使用Chat bot的簡單視頻介紹,筆者在這里拋磚引玉,希望能夠激發大家的好奇心,去大膽使用這些產品,將自己的聰明才智和人工智能技術結合,探索出學習的新方法,攀登上學術的新高峰。
可以預見的是,在2024年剩余的9個多月里,科技巨頭和新秀們將會推出功能更強大的模型和服務更完善的產品,AI行業的發展也將引發持續關注。近日,Anthropic就發布了Claude 3系列大模型,其中功能最強大的模型Opus在各種基準測試中有著優于GPT-4和Gemini 1.0 Ultra的表現,為人工智能領域的火熱競爭添上一把新柴。

一方面,公眾對科技的迅猛發展感到驚喜,但另一方面,網絡社區對“通用人工智能(Artificial General Intelligence)掌控世界”“傳統行業迅速消亡”和“落后的人類被機器取代”等假想情景表達了擔憂。這份焦慮甚至被用作AI課程銷售的噱頭,在短期內造就了“模型未動、賣課先行”的奇觀。
事實上,目前通用人工智能仍然只是一個哲學概念,我們離一個完全具備人類般復雜認知架構的AI系統的誕生還有相當遠的距離。哪怕是引發街頭巷尾熱議的文生視頻大模型Sora,也并非很多自媒體所吹捧的“大世界模型”,或是“物理規律的掌握者”。其核心工作原理是結合了擴散模型和Transformer架構:擴散模型從初始的噪聲出發,逐步細化成所需的視頻內容;而Transformer架構則負責連續視頻幀的處理,確保視頻中動作的流暢度和自然性。AGI的最終實現,也即是讓機器模擬人類的認知過程、理解復雜的概念和環境,并具備自我學習和自適應的能力,仍是需要多學科領域深度合作解決的難題。
在時代的洪流中,與其每天刷手機閱讀媒體關于人工智能的“爆炸式”報道,默默做一個技術革命的旁觀者,不如積極動手,探索如何利用現有的人工智能產品和服務來增強我們的認知能力,而“聊天”機器人則是我們實現這種“智能放大”(Intelligence Amplification)的重要交互平臺。通過上面的簡單介紹其實已可以看出,它能做到不僅僅是陪人類聊天和進行簡單的信息搜索。通過改進提問方式,以及給機器人增加知識庫這一類的“小配件”等方法,我們可以用這些智能體來輔助學習,定制學習材料,甚至讓它們擔任研究助理,承擔簡單的數據分析和可視化等工作。
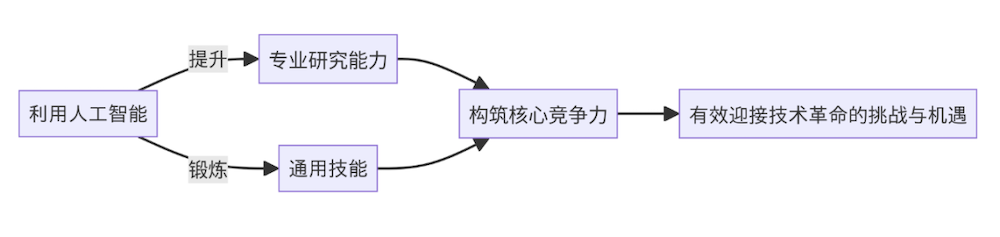
通過運用這種人機協同工作模式,我們能夠把重復性較高的事務交由人工智能機器人去自動化處理,從而提升個人知識的吸收與輸出效率,專注于自身更具創新性的工作。機器人的輔助能夠使我們能夠深入整合專業知識,擴展研究視野,進而激發創新思維。此外,與聊天機器人的互動也是對我們通用能力的一種鍛煉,它幫助我們學會如何更加清晰地“思考”“提問”和“反思”;如何高效整合信息渠道,提高接收信息的質量;以及如何為自己設計并優化一個高效的自動化工作流程。雖然這些能力在傳統的標準化考試中并不是明確的考點,但在學術研究和職場工作中,自主學習探究,提出有效問題,并尋找創新突破能力是具有價值的。綜上所述,借助人工智能,我們不僅能夠提升專業研究能力,還能鍛煉通用技能,從而構筑起自身的核心競爭力,以求有效迎接技術革命的挑戰與機遇。
(本文作者李思玥系paideia.ai提示詞工程師,朱聯璧系復旦大學歷史學系副教授。)



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

