- +1
深度神經(jīng)網(wǎng)絡(luò)壓縮與加速技術(shù)
//
深度神經(jīng)網(wǎng)絡(luò)是深度學(xué)習(xí)的一種框架,它是一種具備至少一個(gè)隱層的神經(jīng)網(wǎng)絡(luò)。與淺層神經(jīng)網(wǎng)絡(luò)類似,深度神經(jīng)網(wǎng)絡(luò)也能夠?yàn)閺?fù)雜非線性系統(tǒng)提供建模,但多出的層次為模型提供了更高的抽象層次,因而提高了模型的能力。深度神經(jīng)網(wǎng)絡(luò)是一種判別模型,可以使用反向傳播算法進(jìn)行訓(xùn)練。隨著深度神經(jīng)網(wǎng)絡(luò)使用的越來越多,相應(yīng)的壓縮和加速技術(shù)也孕育而生。LiveVideoStackCon 2023上海站邀請到了胡浩基教授為我們分享他們實(shí)驗(yàn)室的一些實(shí)踐。
文/胡浩基
編輯/LiveVideoStack
大家好,我是來自浙江大學(xué)信息與電子工程學(xué)院的胡浩基。今天我分享的主題是《深度神經(jīng)網(wǎng)絡(luò)壓縮與加速技術(shù)》。

首先一個(gè)問題是,為什么要做深度神經(jīng)網(wǎng)絡(luò)壓縮?有兩個(gè)原因:第一個(gè)原因是大型的深度神經(jīng)網(wǎng)絡(luò)很難部署在小型化的設(shè)備上。另一個(gè)原因是當(dāng)深度模型越來越大,需要消耗的計(jì)算和存儲(chǔ)資源越來越多,但是物理的計(jì)算資源跟不上需求增長的速度。
從右邊的圖可以看出,從2005年開始,硬件的計(jì)算資源增長趨于放緩,而隨著深度學(xué)習(xí)領(lǐng)域的蓬勃發(fā)展,對算力的需求卻是指數(shù)級(jí)增長,這就導(dǎo)致了矛盾。因此,對深度模型進(jìn)行簡化,降低其計(jì)算量,成了當(dāng)務(wù)之急。近年來,以ChatGPT為代表的大模型誕生,將這個(gè)問題變得更加直接和迫切。如果想要應(yīng)用大模型,必須有能夠負(fù)擔(dān)得起的相對低廉計(jì)算和存儲(chǔ)資源,在尋找計(jì)算和存儲(chǔ)資源的同時(shí),降低大模型的計(jì)算量,將是對解決算力問題的有益補(bǔ)充。
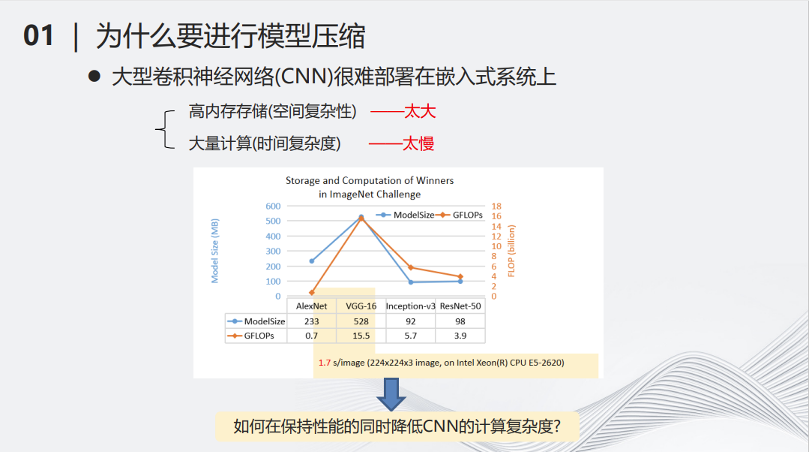
例如2017年流行的VGG-16網(wǎng)絡(luò),在當(dāng)時(shí)比較主流的CPU上處理一張圖片,可能需要1.7秒的時(shí)間,這樣的時(shí)間顯然不太適合用部署在小型化的設(shè)備當(dāng)中。

深度神經(jīng)網(wǎng)絡(luò)的壓縮用數(shù)學(xué)表述就是使用一個(gè)簡單的函數(shù)來模擬復(fù)雜的函數(shù)。雖然這是一個(gè)已經(jīng)研究了幾百年的函數(shù)逼近問題,但是在當(dāng)今的環(huán)境下,如何將幾十億甚至上千億自由參數(shù)的模型縮小,是一個(gè)全新的挑戰(zhàn)。這里有三個(gè)基本思想 -- 更少參數(shù)、更少計(jì)算和更少比特。在將參數(shù)變少的同時(shí),用較為簡單的計(jì)算來代替復(fù)雜的計(jì)算。用低精度量化的比特?cái)?shù)來模擬高精度的數(shù)據(jù),都可以讓函數(shù)的計(jì)算復(fù)雜性大大降低。

深度模型壓縮和加速領(lǐng)域開創(chuàng)人MIT的副教授韓松在2015年的一篇文章,將深度學(xué)習(xí)的模型壓縮分成了如下的5個(gè)步驟。最左邊輸入了一個(gè)深度學(xué)習(xí)的模型,首先要經(jīng)過分解(decomposition),即用少量的計(jì)算代替以前復(fù)雜的計(jì)算,例如可以把很大的矩陣拆成多個(gè)小矩陣,將大矩陣的乘法變成小矩陣的乘法和加法。第二個(gè)操作叫做剪枝(pruning),它是一個(gè)減少參數(shù)的流程,即將一些對整個(gè)計(jì)算不那么重要的參數(shù)找出來并把它們從原來的神經(jīng)網(wǎng)絡(luò)中去掉。第三個(gè)操作叫做量化(Quantization),即將多比特的數(shù)據(jù)變成少比特的數(shù)據(jù),用少比特的加法和乘法模擬原來的多比特的加法乘法,從而減少計(jì)算量。做完以上三步操作之后,接下來需要編碼(encoding),即用統(tǒng)一的標(biāo)準(zhǔn)將網(wǎng)絡(luò)的參數(shù)和結(jié)構(gòu)進(jìn)行一定程度的編碼,進(jìn)一步降低網(wǎng)絡(luò)的儲(chǔ)存量。經(jīng)過以上四步的操作,最后可以得到一個(gè)被壓縮的模型。
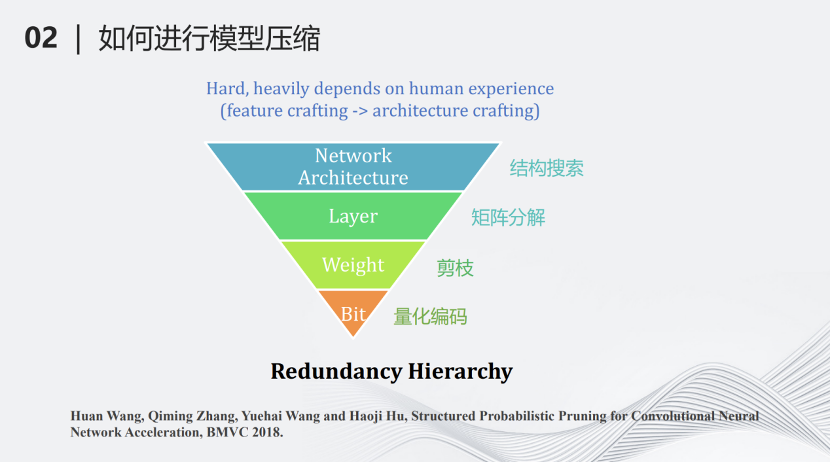
我們團(tuán)隊(duì)提出了另外一種基于層次的模型壓縮分類。最上面一個(gè)層級(jí)叫做網(wǎng)絡(luò)結(jié)構(gòu)搜索(network architecture design),即搜索一個(gè)計(jì)算量較少但對于某些特定任務(wù)很有效的網(wǎng)絡(luò),這也可以看作另一種壓縮方式。第二個(gè)層級(jí)叫做分層壓縮(Layer)。深度學(xué)習(xí)網(wǎng)絡(luò)基本上是分層的結(jié)構(gòu),每一層有一些矩陣的加法和乘法,對每一層的這些加法和乘法進(jìn)行約束,例如將矩陣進(jìn)行分解等,這樣可以進(jìn)一步降低計(jì)算量。第三個(gè)壓縮層級(jí)是參數(shù)(weight),將每一層不重要的參數(shù)去掉,這也就是剪枝。最下面的層級(jí)是比特(bit),用量化對每個(gè)參數(shù)做比特層級(jí)的壓縮,變成量化的編碼。
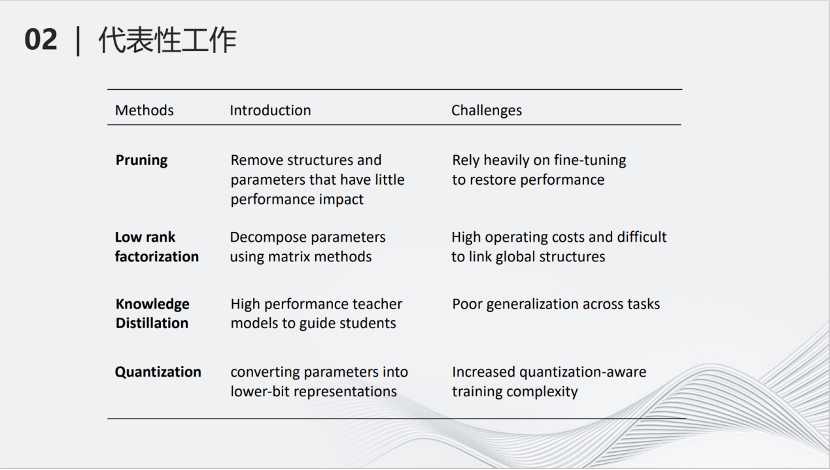
這里是各種壓縮方式的介紹以及它們的挑戰(zhàn)。剪枝(Pruning)減少模型的參數(shù);低秩分解(Low rank factorization)將大矩陣拆成小矩陣;知識(shí)蒸餾(Knowledge Distillation)用大的網(wǎng)絡(luò)教小的網(wǎng)絡(luò)學(xué)習(xí),從而使小的網(wǎng)絡(luò)產(chǎn)生的結(jié)果跟大的網(wǎng)絡(luò)類似;量化(Quantization將深度神經(jīng)網(wǎng)絡(luò)里的參數(shù)進(jìn)行量化,變?yōu)榈捅忍貐?shù),降低計(jì)算量。
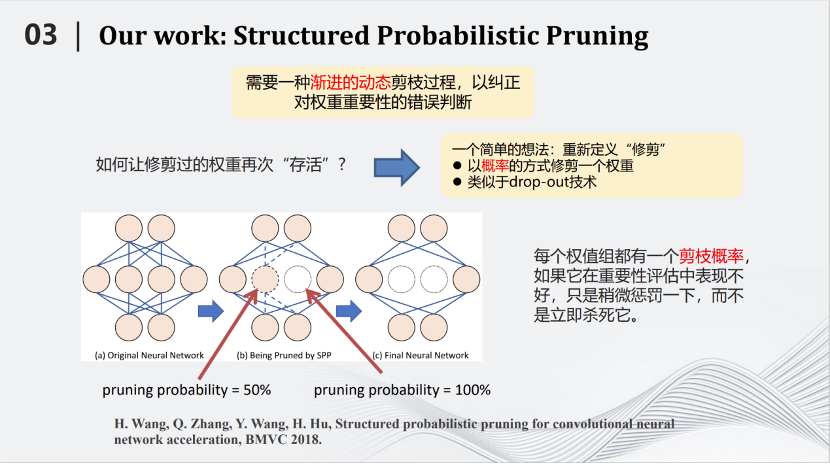
2018年BMVC會(huì)議,我們團(tuán)隊(duì)提出了一種基于概率的剪枝方法,叫做Structured Probabilistic Pruning。這種方法的核心思路是將神經(jīng)網(wǎng)絡(luò)里不重要的參數(shù)去掉。那么如何劃分重要與不重要,是首要問題。最好的標(biāo)準(zhǔn)是去掉某個(gè)參數(shù)以后測試對于結(jié)果的影響。但是在整個(gè)網(wǎng)絡(luò)中那么多的參數(shù),如果每去掉一個(gè)參數(shù)都測試對結(jié)果的影響,時(shí)間就會(huì)非常漫長。所以需要用一些簡單的標(biāo)準(zhǔn),例如參數(shù)絕對值的大小來評(píng)判參數(shù)的重要性。但有一個(gè)矛盾是,簡單標(biāo)準(zhǔn)對于衡量參數(shù)重要性來說并不準(zhǔn)確。那么如何解決上述矛盾呢?我們提出的方案形象一點(diǎn)就是,用多次考試代替一次考試。我們將在訓(xùn)練到一定的地步之后,去掉不重要的參數(shù),這個(gè)過程叫做一次考試。但是每次考試都有偏差。于是我們發(fā)明了這種基于概率的剪枝方法,將一次考試變成多次考試。即每訓(xùn)練一段時(shí)間測試參數(shù)重要性,如果在這段時(shí)間內(nèi)它比較重要,就會(huì)給它一個(gè)較小的剪枝概率,如果在這一段時(shí)間內(nèi)不那么重要,就會(huì)給它一個(gè)較大的剪枝概率。接下來繼續(xù)訓(xùn)練一段時(shí)間,再進(jìn)行第二次考試。在新的考試中,以前不重要的參數(shù)可能變得重要,以前重要的參數(shù)也可能變得不重要,把相應(yīng)的概率進(jìn)行累加,一直隨著訓(xùn)練的過程累加下去,直到最后在訓(xùn)練結(jié)束時(shí),根據(jù)累加的分?jǐn)?shù)來決定哪些參數(shù)需要被剪枝。

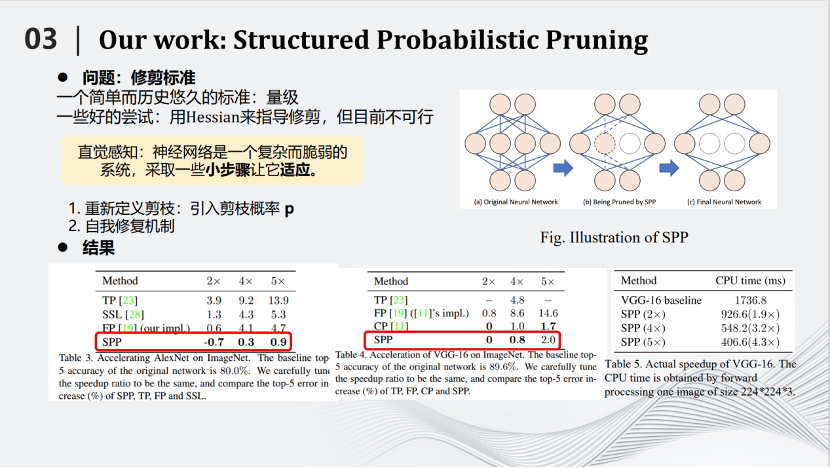
這種方式叫做SPP——Structured Probabilistic Pruning。SPP算法相對于其他的算法有一定的優(yōu)勢,具體體現(xiàn)在左邊的圖片里。例如我們將AlexNet壓縮兩倍,識(shí)別準(zhǔn)確率反而提高了0.7,說明對于AlexNet這樣比較稀疏的網(wǎng)絡(luò)效果很好。從別的圖片也可以看到,相對于其他的算法也有一定優(yōu)勢,這里不詳細(xì)展開介紹。

2020年我們又提出一種基于增量正則化的卷積神經(jīng)網(wǎng)絡(luò)剪枝算法。通過對網(wǎng)絡(luò)的目標(biāo)函數(shù)加入正則化項(xiàng),并變換正則化參數(shù),從而達(dá)到剪枝的效果。

我們通過嚴(yán)格的數(shù)學(xué)推導(dǎo)證明了一個(gè)命題,即如果網(wǎng)絡(luò)函數(shù)是二階可導(dǎo),那么當(dāng)我們增加每一個(gè)網(wǎng)絡(luò)參數(shù)對應(yīng)正則化系數(shù)時(shí),該參數(shù)的絕對值會(huì)在訓(xùn)練過程中會(huì)減小。所以我們可以根據(jù)網(wǎng)絡(luò)參數(shù)的重要程度,實(shí)時(shí)分配其對應(yīng)正則化系數(shù)的增量,從而將一些不太重要的參數(shù)絕對值逐漸壓縮到零。通過這種方式,可以將神經(jīng)網(wǎng)絡(luò)的訓(xùn)練和剪枝融合到一起,在訓(xùn)練過程中逐步壓縮不重要參數(shù)的絕對值,最終去除它們。

相比SPP, 增量正則化方法在AlexNet(ImageNet)上將推理速度提高到原來的4倍,也能夠提高0.2%的識(shí)別率。在將網(wǎng)絡(luò)推理速度提高5倍情況下,識(shí)別率也僅僅下降了0.8,這相比其他壓縮算法也有很大的優(yōu)勢。

增量正則化方法對于三維卷積網(wǎng)絡(luò)的也有一定的壓縮效果,在3D-ResNet18上,將推理速度提高2倍,識(shí)別率下降了0.41%;將推理速度提高4倍,識(shí)別率下降2.87%。

基于增量正則化方法,我們參與了AVS和IEEE標(biāo)準(zhǔn)的制定,提出的算法成功的寫入到國家標(biāo)準(zhǔn)《信息技術(shù) 神經(jīng)網(wǎng)絡(luò)表示與模型壓縮 第1部分 卷積神經(jīng)網(wǎng)絡(luò)》中,同時(shí)也被寫入“IEEE Model Representation, Composition, Distribution and Management”標(biāo)準(zhǔn)中并獲得今年的新興標(biāo)準(zhǔn)技術(shù)獎(jiǎng)。

最近幾年,我們還將深度模型壓縮技術(shù)應(yīng)用到圖像風(fēng)格遷移、圖像超分辨率等底層視覺任務(wù)中。2020年的CVPR論文,我們利用知識(shí)蒸餾來壓縮風(fēng)格遷移網(wǎng)絡(luò)。這里是風(fēng)格遷移網(wǎng)絡(luò)的例子,即輸入兩張圖片,一張是內(nèi)容圖片,一張是風(fēng)格圖片。通過風(fēng)格遷移網(wǎng)絡(luò)生成一張圖片,將內(nèi)容和風(fēng)格融合起來。我們需要做的事就是壓縮風(fēng)格遷移網(wǎng)絡(luò)的大小。
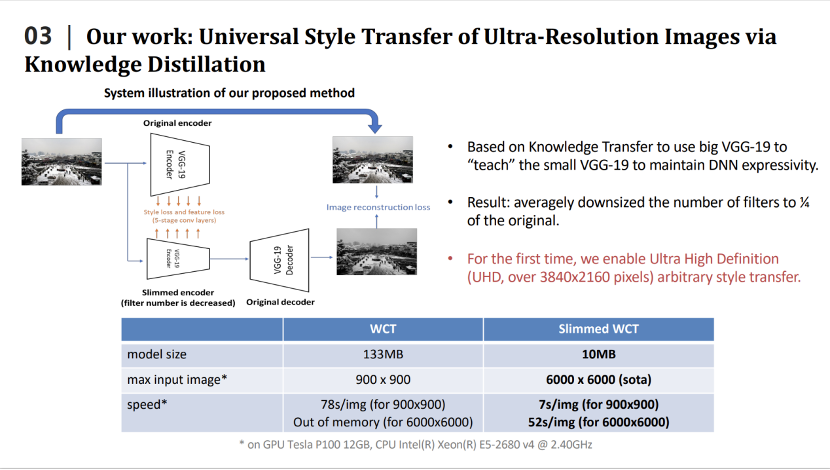
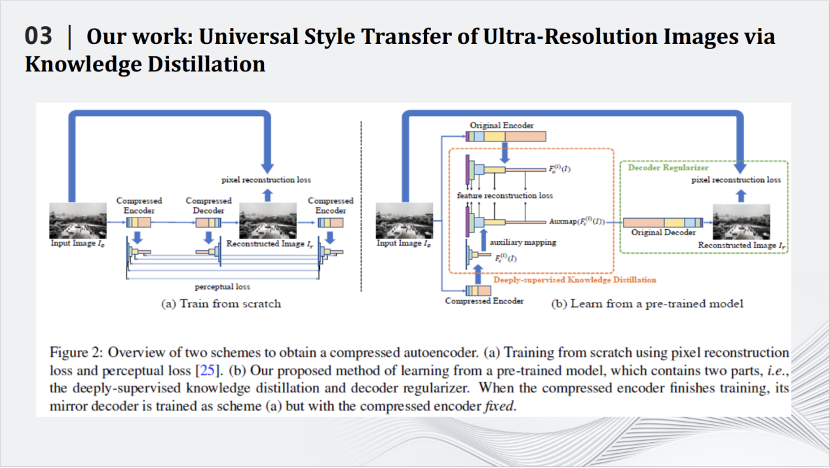
我們利用知識(shí)蒸餾來壓縮風(fēng)格遷移網(wǎng)絡(luò),即設(shè)計(jì)小的學(xué)生模型,用小的學(xué)生模型來模擬大的教師模型的輸出,從而達(dá)到壓縮大的教師模型的目的。我們也設(shè)計(jì)了針對風(fēng)格遷移網(wǎng)絡(luò)的損失函數(shù),更好的完成了知識(shí)蒸餾的任務(wù)。我們提出的方法有很好的性能,例如在2020年效果比較好的WCT風(fēng)格遷移網(wǎng)絡(luò),整個(gè)模型的大小是133m,經(jīng)過壓縮之后只有10m。一塊GPU上使用WCT最多可以同時(shí)處理900×900的圖片,壓縮之后,同樣的GPU上能夠處理6000×6000的圖片,在處理速度上,處理900×900的圖片,WCT需要花費(fèi)78秒,壓縮之后只需要7秒,同時(shí)處理6000×6000的圖片,在單卡的GPU也只要花費(fèi)52秒的時(shí)間。



可以看到,通過我們的模型壓縮技術(shù),即便是4,000萬像素圖片的風(fēng)格遷移,放大后的圖像細(xì)節(jié)依然清晰。

在人臉識(shí)別方面,我們也使用了知識(shí)蒸餾的方法。這是2019年發(fā)表在ICIP的論文,人臉識(shí)別中有個(gè)三元組的損失,即圖片左上角。其中有一個(gè)超參數(shù)m。這個(gè)m是不可以變化的。通過改進(jìn),我們將m變成了一個(gè)可變的參數(shù),這個(gè)參數(shù)能夠由學(xué)生網(wǎng)絡(luò)計(jì)算兩個(gè)圖之間的距離,用距離的方式將m確定下來。基于這種動(dòng)態(tài)的超參數(shù),我們規(guī)劃了知識(shí)蒸餾算法,獲得了不錯(cuò)的效果。

我們實(shí)現(xiàn)了可能是世界上第一個(gè)公開的2M左右的人臉識(shí)別模型,同時(shí)在LFW數(shù)據(jù)上達(dá)到99%以上的識(shí)別率。同時(shí),我們將所做的小型化人臉識(shí)別模型嵌入到芯片中,讓人臉識(shí)別獲得了更多的應(yīng)用。
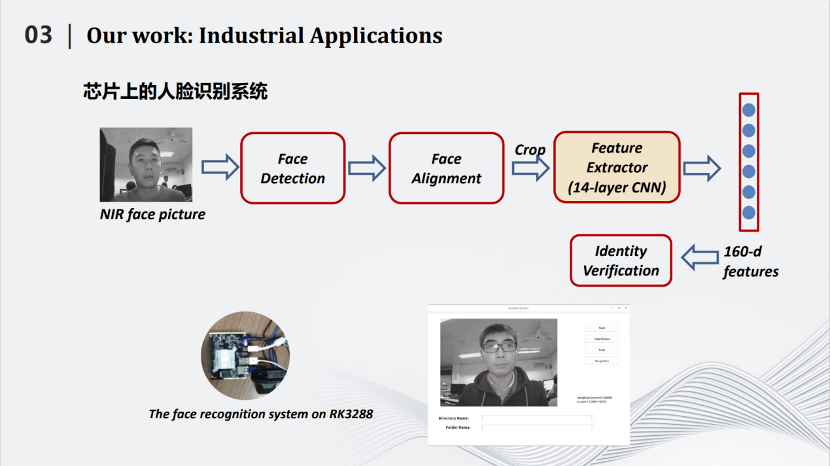

在瑞芯微RK3288上,原有的模型處理一張圖片大概在0.31秒。而我們這個(gè)壓縮后只有2M左右的模型,處理一張圖片的時(shí)間在0.17秒左右。
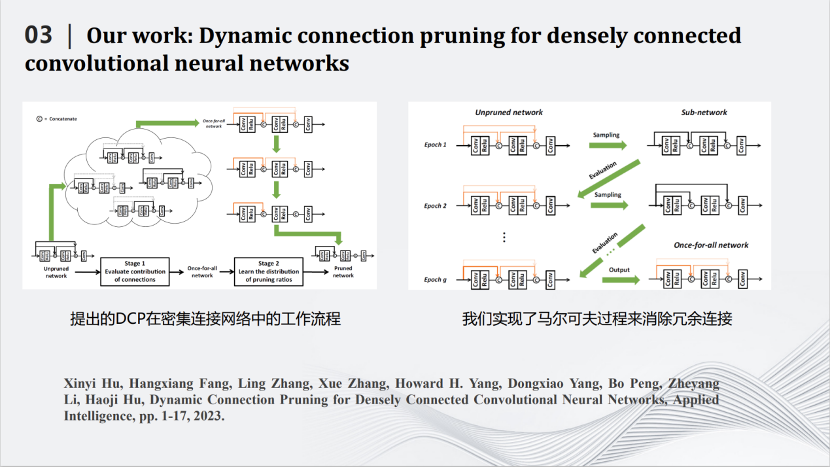
2020年開始,我們和華為合作,將深度壓縮模型應(yīng)用在圖像超分辨率上。卷積神經(jīng)網(wǎng)絡(luò)是一個(gè)先處理局部,再處理全局的模型。而在超分辨率網(wǎng)絡(luò)中,局部信息很重要,需要用跳線連接前面和后面的層。每一個(gè)跳線不僅把數(shù)據(jù)傳送過去,還要同時(shí)將那一層的特征圖傳過去。后面的層不僅僅要處理自己那一層產(chǎn)生的特征圖,還要處理前面?zhèn)魉瓦^來的特征圖。然而,不是每一個(gè)跳線都重要,都需要保留。于是我們規(guī)劃算法,刪除一些不重要的跳線,同時(shí)也刪除了傳送過來的特征圖,從而降低了圖像超分辨率網(wǎng)絡(luò)的計(jì)算量。我們采用馬爾科夫過程建模目標(biāo)函數(shù),消除冗余的跳線,從而完成對超分辨率網(wǎng)絡(luò)的壓縮。
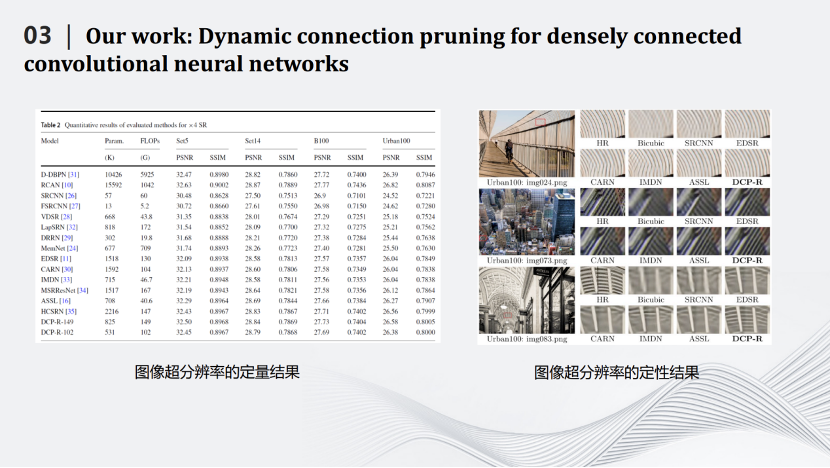
左邊表格是一些定量的結(jié)果。FLOPs是網(wǎng)絡(luò)中加法和乘法的次數(shù)。經(jīng)過壓縮之后的模型DCP-R-102的FLOPs只有102G,與計(jì)算量最大的網(wǎng)絡(luò)D-DBPN相差50多倍的計(jì)算量,而圖像的PSNR和SSIM基本不變。右邊圖片是定性結(jié)果,可見,我們的網(wǎng)絡(luò)DCP-R可以很好的恢復(fù)圖片的紋理和細(xì)節(jié)。

這是關(guān)于圖像超分辨率的另一個(gè)工作。這里我們將將藍(lán)色的大網(wǎng)絡(luò)拆成兩塊,通過互蒸餾(cross knowledge distillation)這種方式進(jìn)一步完成對超分辨率網(wǎng)絡(luò)的壓縮。右圖是具體的定性和定量的結(jié)果。

這篇發(fā)表在期刊Pattern Recognition上的文章所做的事情是對深度模型進(jìn)行量化。最極致的量化叫做二值化(binarization),即對每個(gè)參數(shù)只用+1和-1兩個(gè)值來表示。如果每個(gè)參數(shù)都只是+1和-1,那么網(wǎng)絡(luò)計(jì)算中矩陣的乘法將可以變?yōu)榧訙p法,這樣就比較適用于類似FPGA這種對于乘法不友好的硬件系統(tǒng)中。但是二值化也會(huì)帶來一定的壞處,由于每個(gè)參數(shù)取值范圍變小,整個(gè)網(wǎng)絡(luò)的性能會(huì)有極大的下降。我們在將網(wǎng)絡(luò)二值化的同時(shí),為網(wǎng)絡(luò)加一些輔助的并行結(jié)構(gòu),這些并行結(jié)構(gòu)是通過網(wǎng)絡(luò)搜索出來的,也都是一些二值化的分支,即圖中紅色的部分。加入并行結(jié)構(gòu)后一方面讓二值化的性能有了提升,另一方面也讓計(jì)算增量保持在可控的范圍內(nèi)。利用下方的公式,綜合考量精度(accuracy)、特征圖相似性(similarity)和復(fù)雜度(complexity)三個(gè)方面,構(gòu)造目標(biāo)函數(shù),在提高精度的前提下盡量減小復(fù)雜度,從而達(dá)到模型精度和復(fù)雜度的平衡。最近我們也在嘗試使用重參數(shù)化的方式,將這些增加的結(jié)構(gòu)合并到以前的網(wǎng)絡(luò)當(dāng)中,從而使網(wǎng)絡(luò)結(jié)構(gòu)不發(fā)生改變的前提下,進(jìn)一步增加網(wǎng)絡(luò)二值化的效果。
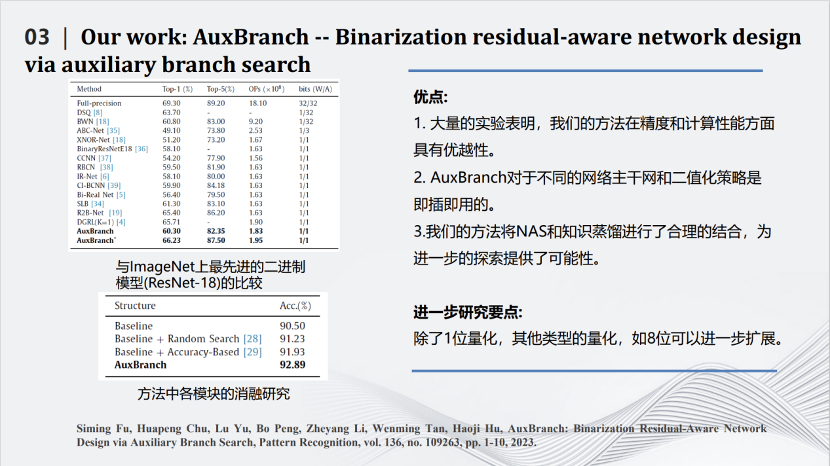
在ResNet-18上可以看到,使用上述方法可以把90.5%的識(shí)別準(zhǔn)確度變成92.8%,同時(shí)計(jì)算量沒有提升特別多。
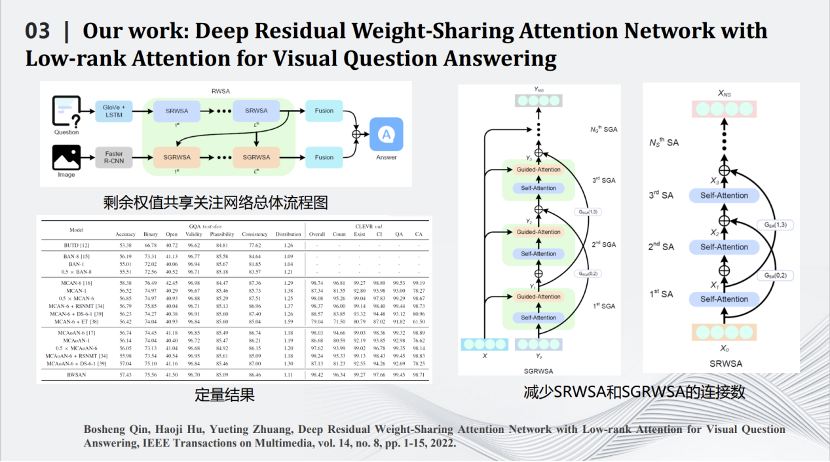
我們也是比較早做Transformer壓縮的實(shí)驗(yàn)室。Transformer壓縮的第一步是用矩陣?yán)碚搶ransformer中Q、K、V三個(gè)矩陣進(jìn)行分解,用小的矩陣相乘和相加代替大矩陣的相乘。通過一些理論推導(dǎo),證明在特定場合下相比原有的矩陣計(jì)算準(zhǔn)確度上界會(huì)有一定提升。壓縮的第二步是減掉Transformer網(wǎng)絡(luò)里的跳線。通過這兩個(gè)相對簡單的壓縮方式完成對Transformer網(wǎng)絡(luò)的壓縮,同時(shí)將其用在智能視覺問答任務(wù)中。
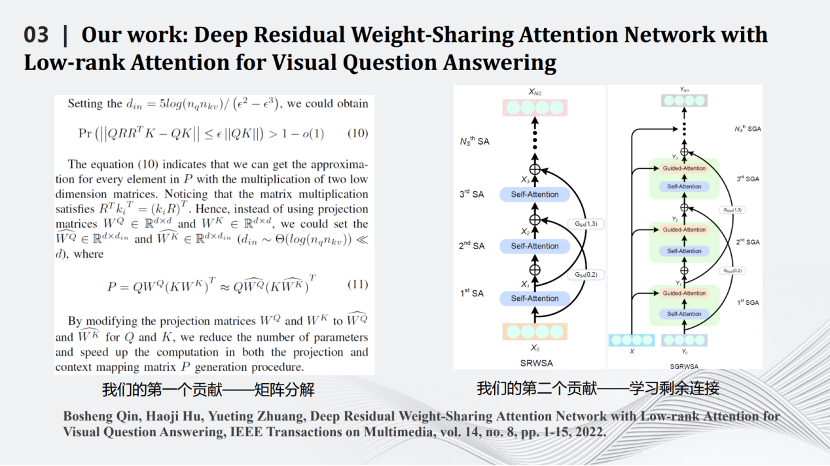
這是一些定量和定性結(jié)果的比較,可以看到我們的算法在保留原來性能的同時(shí)大幅度減少了網(wǎng)絡(luò)的計(jì)算量。


最后,講一下我認(rèn)為這個(gè)領(lǐng)域可能有前途的未來發(fā)展方向。
首先,利用神經(jīng)網(wǎng)絡(luò)壓縮技術(shù)彌補(bǔ)大規(guī)模語言和視覺基礎(chǔ)模型的不足是迫在眉睫的方向。大模型消耗過多的計(jì)算量和存儲(chǔ)量,如何將大模型變小是一個(gè)重要的科學(xué)問題。一些具體的問題包括,如果大模型是可以做100種任務(wù)的通才,那么如何將其轉(zhuǎn)變?yōu)橹荒茏?種任務(wù)小模型,也就是專才?這里有很多空間,值得繼續(xù)挖掘。
第二,針對流行的特定任務(wù)網(wǎng)絡(luò)進(jìn)行壓縮,例如Nerf和擴(kuò)散模型等。但是,如果我們不能在方法上有所創(chuàng)新,只是一昧追逐流行的網(wǎng)絡(luò)進(jìn)行壓縮,也會(huì)陷入內(nèi)卷的困境。
第三,我認(rèn)為軟硬結(jié)合的的網(wǎng)絡(luò)壓縮算法是值得深入研究的方向。將硬件參數(shù)和硬件結(jié)構(gòu)作為優(yōu)化函數(shù)的一部分寫入到網(wǎng)絡(luò)壓縮算法中,這樣壓縮出來的網(wǎng)絡(luò)就能夠直接適配到專門的硬件上。
第四,神經(jīng)網(wǎng)絡(luò)壓縮算法和通信領(lǐng)域的結(jié)合。例如增量壓縮,即設(shè)計(jì)神經(jīng)網(wǎng)絡(luò)壓縮算法,在發(fā)送端首先傳輸網(wǎng)絡(luò)最重要的部分,接收端首先收到一個(gè)識(shí)別精度較低的模型;隨著更多的傳輸,接收端能逐步接收到越來越精確的模型。這個(gè)想法與圖像或視頻的壓縮類似,可以完成神經(jīng)網(wǎng)絡(luò)模型在不同環(huán)境和資源下的個(gè)性化部署。
最后,我比較關(guān)注的是理論方面的研究,我暫且把它稱為深度神經(jīng)網(wǎng)絡(luò)的信息論。目前的模型壓縮算法設(shè)計(jì)主要靠經(jīng)驗(yàn),欠缺理論基礎(chǔ)。一個(gè)重大的理論問題是,對于特定的任務(wù)、數(shù)據(jù)和網(wǎng)絡(luò)架構(gòu),實(shí)現(xiàn)特定的精度所需要的最小計(jì)算是多少?這個(gè)問題當(dāng)然是有一個(gè)明確的答案,但目前我們離這個(gè)答案仍然非常遙遠(yuǎn)。就像香農(nóng)的信息論在通信領(lǐng)域的基礎(chǔ)地位一樣,我們也期待深度神經(jīng)網(wǎng)絡(luò)的信息論早日誕生。
我的演講就到這里,以下是我們實(shí)驗(yàn)室的網(wǎng)頁、聯(lián)系方式,以及一些開源的代碼,歡迎有興趣的聽眾和我們聯(lián)系。謝謝大家。
本文為澎湃號(hào)作者或機(jī)構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機(jī)構(gòu)觀點(diǎn),不代表澎湃新聞的觀點(diǎn)或立場,澎湃新聞僅提供信息發(fā)布平臺(tái)。申請澎湃號(hào)請用電腦訪問http://renzheng.thepaper.cn。


- 澎湃新聞微博
- 澎湃新聞公眾號(hào)

- 澎湃新聞抖音號(hào)
- IP SHANGHAI
- SIXTH TONE
- 報(bào)料熱線: 021-962866
- 報(bào)料郵箱: news@thepaper.cn
滬公網(wǎng)安備31010602000299號(hào)
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報(bào)業(yè)有限公司

