- +1
通話降噪算法在手機(jī)和IOT設(shè)備上的應(yīng)用和挑戰(zhàn)
隨著電子產(chǎn)品的升級換代,用戶對通話質(zhì)量的要求也越來越高。通話降噪算法對通話質(zhì)量起到了關(guān)鍵核心的作用。計算資源的提升使得深度學(xué)習(xí)模型在便攜式的低功耗芯片上面跑起來了,器件成本降低讓IoT設(shè)備開始使用骨導(dǎo)傳感器,,那怎么樣才能將深度學(xué)習(xí)和傳統(tǒng)算法結(jié)合?怎么樣充分利用好骨導(dǎo)傳感器?怎么樣將客觀測試的結(jié)果轉(zhuǎn)化為真實的用戶體驗?這也是新時期通話算法面臨的新的挑戰(zhàn)。LiveVideoStackCon 2022北京站邀請到了王林章老師,為我們分享通話降噪算法在手機(jī)和IOT設(shè)備上的應(yīng)用和挑戰(zhàn)。
文/王林章
整理/LiveVideoStack
大家上午好。今天我?guī)淼姆窒眍}目是:通話降噪算法在手機(jī)和IoT設(shè)備上的應(yīng)用和挑戰(zhàn)。

先看一下國家統(tǒng)計局的數(shù)據(jù),在2021年全國通話時長有 4. 56 億萬分鐘,基本上平均每人每天至少有 10 分鐘的通話時間。
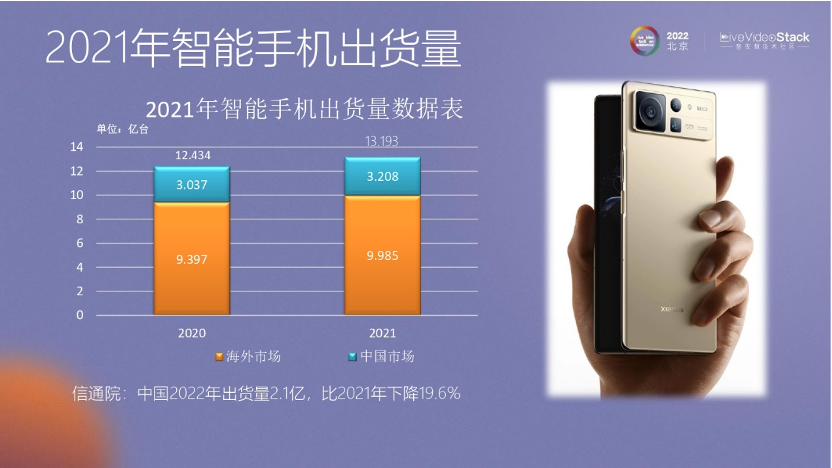
手機(jī)保有量也非常大,在 21 年底有18. 56 億部手機(jī)。如果根據(jù)中國有14 億人口的話,可能還有4億多人有兩個手機(jī)。
21年智能手機(jī)出貨量的數(shù)據(jù)是13億臺,22年的數(shù)據(jù)量有所下降,大約在 11 億臺。

然后是 TWS 耳機(jī)的出貨量,在 22 年大約有 3. 5 億臺,也在穩(wěn)步增長,所以這個算法也在不停運作。

今天我從五個方面講一下通話降噪算法落地的狀態(tài):
首先,通話降噪算法的評價方法,怎么樣的算法才是最好的算法?其次,通話降噪算法的背景介紹。最后,介紹通話降噪算法面臨的挑戰(zhàn)、落地的實踐和未來的展望。
-01-
通話降噪算法的評價方法

首先介紹一下:什么是語音,什么是噪聲。
我們一般把語音分為兩類:清音和濁音。清音,一般指聲帶不發(fā)音;濁音,聲帶發(fā)音。從圖頻譜上看,濁音會有很多基音和諧波,清音基本沒有,就像白噪聲。清音和濁音并不是指一個字,而是在音節(jié)里有清音和濁音的區(qū)別。
噪聲分為很多種。常見的噪聲,有馬路噪聲、地鐵噪聲、施工的噪聲。還有一些特殊噪聲,如風(fēng)噪、共振噪聲,因為這些噪聲對算法的挑戰(zhàn)更高,所以把它們列為特殊噪聲。
關(guān)于噪聲的分類,如果從算法的角度來講,傳統(tǒng)算法都可以處理好一般的平穩(wěn)噪聲。
根據(jù)空間的特性,可以分為方向性噪聲和擴(kuò)散場噪聲,一般用陣列算法來處理。
此外,根據(jù)頻帶的寬度,又分為窄帶和寬帶噪聲。圖里有清音和濁音的標(biāo)注,濁音會有比較清晰的諧波成分;清音就像白噪聲,是一個比較平穩(wěn)的狀態(tài)。

我們大致理解一下噪聲的范圍。在生活中,比如會議室,如果不說話,可能是40到80dB的噪聲場景。到了馬路上,如果有汽車通過,一般是70到 80 dB。如果在地鐵上,地鐵呼嘯而來的噪聲可能會到90 dB。酒吧、KTV 里的噪聲可能到了100 dB。飛機(jī)發(fā)動機(jī)就更大了,可能有110到130dB的噪聲。
后文會給大家一些建議,看看什么樣的噪聲場景對我們危害比較大。
再說一下語音的聲壓級范圍。一般耳語是在50 dB,正常說話可能在60 dB,不包括用擴(kuò)音器。如果用擴(kuò)音器,聲音在 100 dB左右。大聲喧嘩一般是80dB,歌唱家一般在 90dB左右,但是最高能達(dá) 130dB。
左邊的圖顯示了什么樣的噪聲對我們的影響最大。其實,在130dB 的情況下,我們只要在這個環(huán)境里待兩分鐘,那么聽力就可能受傷害了,也許就不能再恢復(fù)了。
然后再看一下聽力在KTV中的狀態(tài),KTV 里的噪聲大約在 100 dB 左右,如果在這個環(huán)境里待過兩個小時或超過兩個小時,聽力也會受到傷害,而且這種傷害是不能恢復(fù)的。
所以,給大家一個建議:不要在KTV里待太長時間,兩個小時足夠了,超過兩個小時可以去休息一下,保護(hù)自己的聽力。
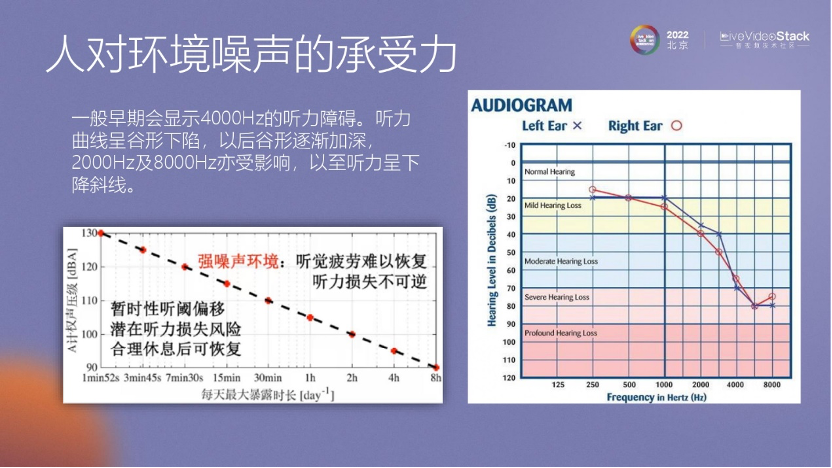
再看一下,如果耳朵受損,會是一個什么樣的狀態(tài)。這里有一個數(shù)據(jù),在正常播放的情況下,能夠聽得很清晰。在1000赫茲的情況下,如果正常播放的聲音聽不清楚了,要加大到約 20 dB 以上才能聽清的話,那么耳朵就已經(jīng)受到嚴(yán)重的傷害了。這時根據(jù)中國醫(yī)學(xué)的數(shù)據(jù)來看,在 4000赫茲的環(huán)境里,可能要加到 70—80 dB 才能聽清。所以如果耳朵受傷,可能最初聽到的聲音是很悶的。和大家強(qiáng)調(diào)一下,保護(hù)聽力還是很重要的。

國際標(biāo)準(zhǔn)如何規(guī)范通話降噪的參數(shù)?
ITU出了一系列參數(shù),因為我們在做通話降噪,所以最關(guān)注P800 這個協(xié)議,它是關(guān)于通話降噪評價非常多的一個標(biāo)準(zhǔn),大家如果有興趣可以去找原文看一下。
還有P830、805等一系列標(biāo)準(zhǔn),大部分都是給音頻和語音的編解碼,用于音頻的質(zhì)量的判斷,speech 也會有編解碼質(zhì)量的損傷,所以也有一些標(biāo)準(zhǔn)對此進(jìn)行規(guī)范。
右邊的第一張圖是天津大學(xué)的老師在做的關(guān)于信噪比對可懂度的評價。我們發(fā)現(xiàn)當(dāng)信噪比在0dB 的時候,可懂度基本在 50% 左右。當(dāng)信噪比大于0,如果超過 10dB ,可懂度在 80dB的80% 以上,所以這時的可懂度是比較好的。當(dāng)信噪比低于- 5dB時,可懂度就非常差了。

我們有一些通話和評測要求,這些要求會更加嚴(yán)格。在測試時,我們進(jìn)行了嚴(yán)格的檢驗。例如要求測試時手機(jī)的通話時間,如打電話一小時或兩小時,在不同環(huán)境下保持算法穩(wěn)定運行。另外,當(dāng)拿起手機(jī)時,我們會堵住底部的麥克風(fēng),這時即便通話也不能說話,因為底部的麥克風(fēng)被堵上,聲音無法傳遞。這是我們自己的測試要求。
剛才提到了一個重要的通話標(biāo)準(zhǔn),即ITU標(biāo)準(zhǔn)里的P800。這個標(biāo)準(zhǔn)通常采用五分制評分。在算法開發(fā)過程中,我們通常無法完全達(dá)到4到5分的水平,因為這個要求非常高。因此,我們主要追求達(dá)到3到4分的水平,即聽起來非常清晰,但可能會有一些雜音。
當(dāng)然,如果得分在1到2分之間,這基本上是不可接受的;而得分在2到3分之間是可以的,意味著仍然可以進(jìn)行交流,但可能存在一定的延遲。因此,在惡劣情況下,也可能出現(xiàn)2到3分的情況,能夠確保可以通話,但音質(zhì)可能不是很好。

在這里,我具體列舉了具體參數(shù)。當(dāng)做深度學(xué)習(xí)模型訓(xùn)練時,我們通常會關(guān)注到PESQ分和STOI分,這是短時主觀的可懂度的評估。比如第三個TMOS分?jǐn)?shù),它評估的是在沒有噪聲的情況下使用手機(jī)打電話后,對方接收到的語音質(zhì)量如何。大家可能會有一個疑問,即在沒有噪聲的情況下打電話,那傳輸?shù)恼Z音應(yīng)該非常好,理論上講確實應(yīng)該非常好。但是,我們發(fā)現(xiàn),算法可能會破壞語音,或者在傳輸過程中造成破壞。因此,TMOS是對傳輸過程中沒有噪聲且語音沒有受損的情況下的評估。接下來,我們再看看NMOS和SMOS,它們是在噪聲環(huán)境下對語音進(jìn)行評估的。NMOS評估的是在噪聲環(huán)境下打電話后,抑制噪聲水平如何?抑制得越多,NMOS分?jǐn)?shù)就越高。SMOS評估的是在噪聲環(huán)境下打電話后,經(jīng)過鏈路傳輸后的語音的保證度如何?語音保證度越好,得分就越高。
所以,看起來SMOS和NMOS的分?jǐn)?shù)有些矛盾,因為抑制得越多,可能損傷的語音也越多,而如果要求語音保證很好,降噪水平可能就達(dá)不到目標(biāo)要求。因此,有一個綜合的評分叫做GMOS分?jǐn)?shù)。GMOS分?jǐn)?shù)綜合了SMOS和NMOS的評分,從而得出一個結(jié)果。
TMOS、SMOS、NMOS以及GMOS是評價通話質(zhì)量時非常重視的幾個參數(shù)。目前,有一些趨勢,就是大家還不太相信GMOS,如小米采用的評估方式是將SMOS和NMOS的平均值作為評價標(biāo)準(zhǔn),而不是用GMOS。

小米的通話評估是在全消聲室中進(jìn)行的,目前所有的通話都會在這樣的消聲室中進(jìn)行評價。噪聲復(fù)原系統(tǒng)有6個揚聲器,周圍有6個揚聲器來進(jìn)行噪聲復(fù)原。我們的手機(jī)是標(biāo)準(zhǔn)裝卡,包括嘴巴與揚聲器的距離以及耳朵與聽筒的距離。這是我們的標(biāo)準(zhǔn)評價測試系統(tǒng)。
-02-
通話降噪算法的基礎(chǔ)介紹
在介紹完語音通話評價后,我們繼續(xù)探討算法的技術(shù)。
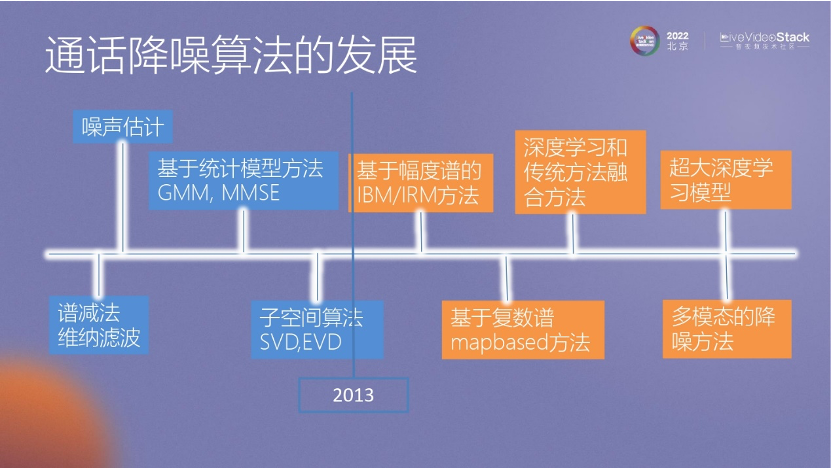
首先,我們來看一下通話降噪算法的發(fā)展過程。最早,大家可能都知道譜減法、噪聲估計這些早期的算法,后來的數(shù)據(jù)處理中也會用到類似的方法,例如高斯混合模型(GMM)算法和子空間算法,目前我們也在使用矩陣分解方法,如IV。
從2013年開始,深度學(xué)習(xí)在降噪領(lǐng)域發(fā)揮了強(qiáng)大的能力,尤其在抑制非平穩(wěn)狀態(tài)方面表現(xiàn)出色。早期的方法基于掩蔽曲線和頻譜掩蔽,后來逐步升級,出現(xiàn)了基于復(fù)數(shù)譜mapbased方法。

目前,我們采用深度學(xué)習(xí)與傳統(tǒng)方法相結(jié)合的方式進(jìn)行降噪。我認(rèn)為未來的趨勢可能是采用多模態(tài)的降噪方法以及訓(xùn)練超大模型,這種降噪方法可能與目前熱門的GPT模型以及超大模型的輸出相關(guān)。

在通話降噪領(lǐng)域,從2012年到2013年,深度學(xué)習(xí)的引入可以被視為一個里程碑。其中有兩篇文章具有重要意義:一篇是斯坦福的文章,在語音識別方面,通過抑制噪聲,提高了魯棒性;另一篇是2013年王德亮老師在語音分離方面引入了機(jī)器學(xué)習(xí)的方法。

我把通話降噪里比較經(jīng)典的文章列在圖中,這里有一個過程:早期我們用什么樣的方法去做語音降噪,到后來我們逐步深入提升它的效果。
在早期階段,徐勇在降噪研究中引用了一種稱為"Dense"的方法,即線性層,取得了較好的降噪效果,這是早期取得較好降噪效果的一篇文章。然而,這種"Dense"層的計算量較大,并且效果有所欠缺,因為它所學(xué)習(xí)的東西類似于統(tǒng)計規(guī)律。
因此,從2016年開始,高通在研究中引入了一種被稱為"CN"的卷積網(wǎng)絡(luò)。卷積網(wǎng)絡(luò)的好處在于它能夠?qū)W習(xí)頻域之間的頻譜信息,所以具有更好的效果。
在2018年,有兩篇文章也值得提及。一篇是由李錦輝老師在引入LSTM 的時候,提出的基于遞歸的RNN的模型,而另一篇則是大家比較熟悉的RNN方案,其參考代碼在網(wǎng)上可獲取。其模型具有非常低的計算量,但帶來了非常好的降噪效果。它采用了傳統(tǒng)降噪思路,包括降噪模型和樹狀濾波過程,這些細(xì)節(jié)較為復(fù)雜,但總的來說,這篇文章在早期為大家提供了有價值的參考。
隨著對深度學(xué)習(xí)的研究,在2020年ICASSP舉辦了一個降噪比賽。西北工業(yè)大學(xué)的老師開發(fā)了DCCRN模型,效果是非常驚艷,在2020年的比賽中拿到第一名。
在2021年的比賽里,聲學(xué)所的李曉東老師團(tuán)隊提出了一個分階段降噪的模型,在處理混響的情況下表現(xiàn)更出色,也獲得了第一名。
因此,總體來看,發(fā)展方向是從DNN到CNN,再到RNN,然后進(jìn)一步發(fā)展為更為復(fù)雜的深度學(xué)習(xí)DCCRN模型。
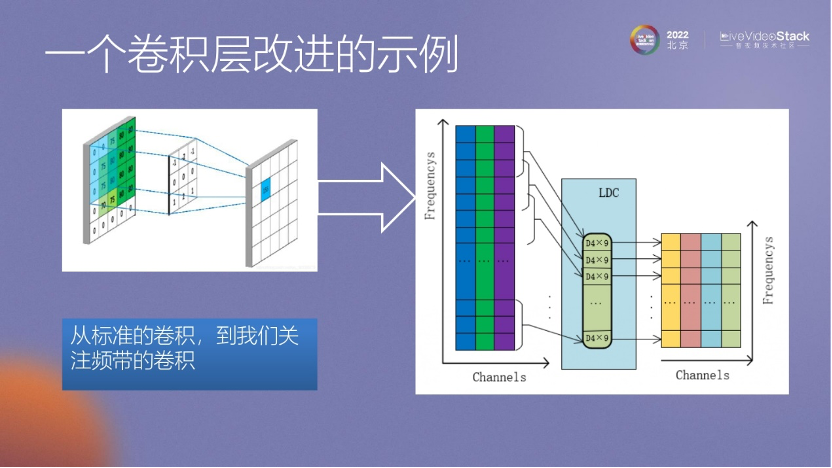
這里我想提一下我們自己的工作,之前介紹的都是其他老師在降噪研究方面的工作,而我們在這個領(lǐng)域做了一點簡單的改進(jìn)。在前面介紹語音和噪聲的情況時,提到語音除了基頻和諧波外,還可能有共振峰等概念。所以,我們認(rèn)為在卷積層上不一定需要在整個頻譜范圍內(nèi)都做卷積。我們嘗試了一種改進(jìn)方式,即只對關(guān)注的低頻部分進(jìn)行卷積,然后再對關(guān)注的高頻部分進(jìn)行卷積。

這里的原始數(shù)據(jù)是一個嬰兒的哭聲。嬰兒的哭聲與人的聲音非常相似,也有基頻和諧波,因此對其進(jìn)行降噪是非常難的。
我們再聽一下在使用小模型時的輸出結(jié)果,這個聲音可能會聽起來有些沉悶,這是因為在收斂過程中保留了一些嬰兒的哭聲。
再看一下訓(xùn)練的大模型的結(jié)果,基本上可以聽到大模型對嬰兒哭聲的抑制效果非常好。語音的清晰度也還可以,基本上能聽得清楚。根據(jù)前文所提的MOS打分,估計大模型的評分應(yīng)該在3分左右,而小模型可能是2分多。
這是一個基礎(chǔ)的概念,深度學(xué)習(xí)方面的內(nèi)容講完后,我們還需要看一下傳統(tǒng)算法,因為在通話降噪領(lǐng)域,傳統(tǒng)算法仍然發(fā)揮著重要作用。
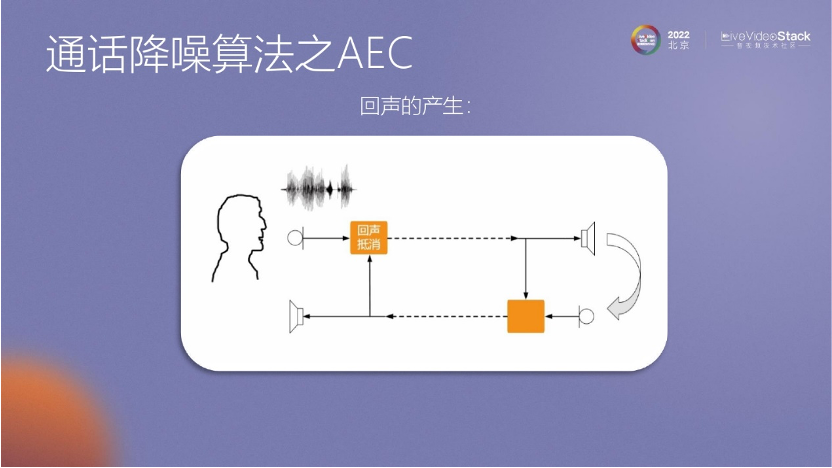
這里展示了回聲產(chǎn)生的過程:有一個說話人發(fā)出聲音,聲音通過路徑傳播,如果在下方黃色框內(nèi)沒有用算法進(jìn)行處理,聲音會通過麥克風(fēng)進(jìn)入耳朵。

在回聲消除的算法中,最早期是采用牛頓迭代方法,它是一種簡單的方法,通過誤差和梯度迭代計算W因子。然而,這種方法存在一些問題,比如如何處理雙重回聲、共享環(huán)境、怎么確定濾波器長度、收斂速度以及非線性問題等。
所以我列出了一些簡單的建議。例如,在設(shè)計濾波器時,考慮到復(fù)雜的混響環(huán)境,不一定需要使用很長的濾波器,可以使用其他方法。

此外,關(guān)于AEC,現(xiàn)在也有使用神經(jīng)網(wǎng)絡(luò)的方法,它的優(yōu)點是語音保真度更好。目前有兩種方法,一種是讓神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)整個過程,將麥克風(fēng)的數(shù)據(jù)和參考信號輸入網(wǎng)絡(luò),讓網(wǎng)絡(luò)自己學(xué)習(xí)和處理回聲抑制;另一種方法是將傳統(tǒng)算法的結(jié)果和參考信號一起提供給神經(jīng)網(wǎng)絡(luò)進(jìn)行處理。這兩種方法都各有優(yōu)勢,但是神經(jīng)網(wǎng)絡(luò)的計算量非常大,與傳統(tǒng)方法相比,計算量的問題讓我們很難接受。
所以,我們也在考慮一個問題,即是否將降噪效果也整合到回聲抑制中。我們正在嘗試這件事,即讓神經(jīng)網(wǎng)絡(luò)既處理回聲抑制,又進(jìn)行降噪處理。

在2022年,我們參與了ICASSP的AEC挑戰(zhàn)賽。我們發(fā)表了一些相關(guān)文章,取得了還不錯的效果。特別是在低信回比的情況下,比如-5dB,甚至-50dB下,我們的方法仍然能夠獲得良好的效果。我們使用了一些熱門的技術(shù),比如Transformer,這是一種神經(jīng)網(wǎng)絡(luò)模型。但是,因為它的計算量較大,所以目前只是做了一些演示,并沒有落地應(yīng)用。另外,關(guān)于AEC,可能還涉及到一些陣列算法,適用于手機(jī)應(yīng)用和IOT應(yīng)用。
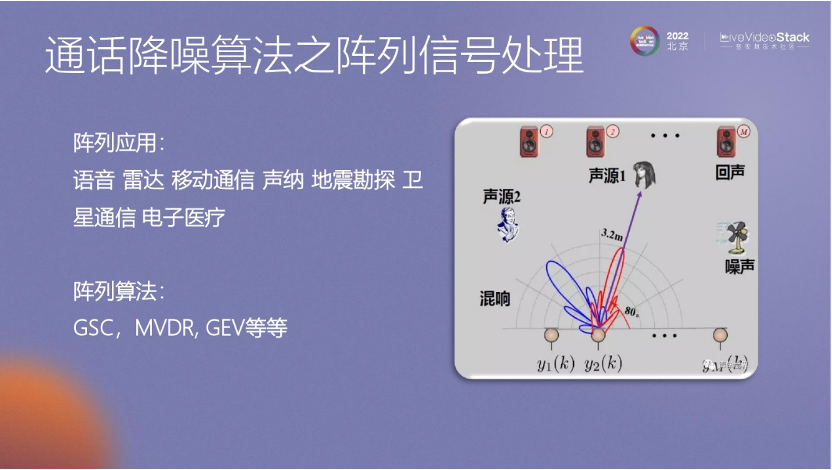
陣列算法主要用于實現(xiàn)方向性的信號抑制,其中包括一些常見的算法,如GSC、MVDR、GEV等。這些算法的主要目標(biāo)是求出麥克風(fēng)陣列與聲源方向之間的關(guān)系。具體的推導(dǎo)過程可以在相關(guān)資料中找到。
通過陣列算法,我們可以得到麥克風(fēng)陣列擺放位置與聲源方向之間的關(guān)系。這個推導(dǎo)過程的好處在于可以了解每個麥克風(fēng)接收到信號時會出現(xiàn)什么樣的差異。
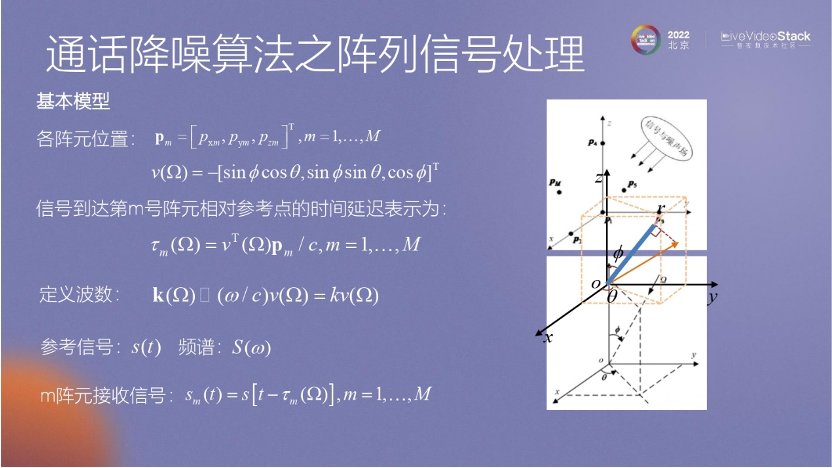
陣列算法的推導(dǎo)過程涉及到對陣列接收信號的標(biāo)注以及確定目標(biāo)方向矩陣。在推導(dǎo)過程中,可以使用簡單的陣列算法,如CBF算法。CBF算法的基本思路是通過比較每個麥克風(fēng)接收到的信號來確定最優(yōu)的狀態(tài),這是CBF算法的最簡單過程。

這里我們在做一件最重要的事情,就是確定兩個麥克風(fēng)之間接收信號的區(qū)別。其中最關(guān)鍵的因素可能是延時差異。雖然整個推導(dǎo)過程可能非常復(fù)雜,但它計算了延時對兩個麥克風(fēng)的影響。

CBF 只是理論上的推導(dǎo),MVDR是我們真正使用的算法。MVDR算法的主要思路是通過約束條件來保證方向位的正確性,并使用拉格朗日算子來最小化目標(biāo)函數(shù)并最大化目標(biāo)信號,同時最小化其他方向的噪聲信號。
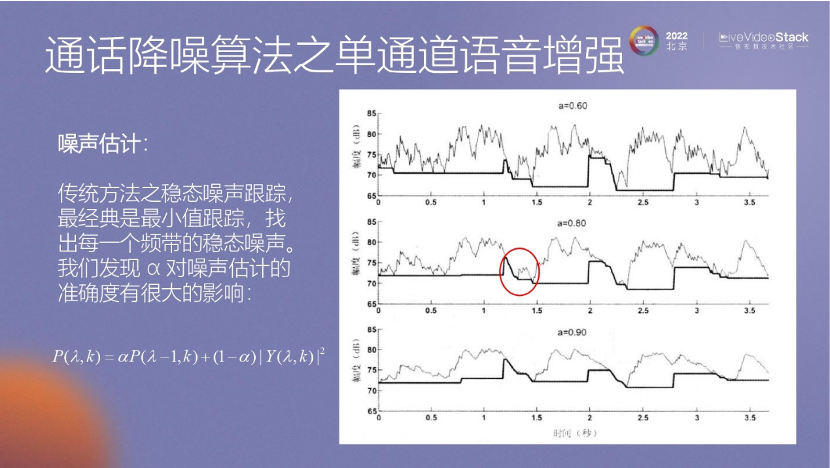
對于單通道降噪問題,早期的方法是基于能量估計。通過計算信號在頻段上的能量,并跟蹤最小值,如果最小值不為零,那么它就被認(rèn)為是這個平臺里的噪聲。
我們在實際應(yīng)用中,發(fā)現(xiàn)平滑能量計算對結(jié)果的影響非常大。這里可以看到Alpha因子對噪聲估計的準(zhǔn)確度影響很大。

單通道降噪升級在這個基礎(chǔ)上提出了一種基于信噪比的迭代評估方法,通過判斷平滑和改進(jìn)來獲得更好的降噪效果,這算是傳統(tǒng)算法里的迭代升級。
-03-
通話降噪面臨的挑戰(zhàn)
我們再看一下算法面臨的挑戰(zhàn)。
我們在手機(jī)、IOT以及在其他設(shè)備上的應(yīng)用的時候,面臨的最大問題就是計算資源。因為現(xiàn)在和以前不同,以前是傳統(tǒng)算法,計算的容量有限。但是現(xiàn)在有深度學(xué)習(xí)這個模型。深度學(xué)習(xí)模型在語音降噪領(lǐng)域取得了顯著的進(jìn)展。這些模型的效果與模型的規(guī)模相關(guān),越大的模型能夠?qū)W習(xí)越多。如果想要實現(xiàn)更好的效果,關(guān)鍵是要確保足夠的計算資源,所以這也依賴于硬件的不斷發(fā)展。
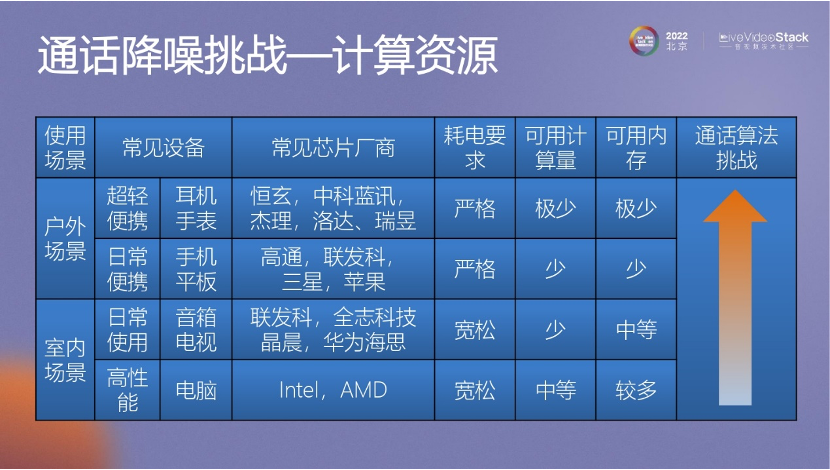
雖然電腦上的計算資源較為充足,但在可穿戴設(shè)備(如小米SE手表)上,需要不停地優(yōu)化手機(jī)里的算法,以便應(yīng)用到手表、耳機(jī)上。

比如在電腦上,內(nèi)存資源用1M以上也無所謂。然而,在手機(jī)上,可用的資源較為有限,可能只有幾百K的內(nèi)存可供使用。而在IOT設(shè)備上,通常只能分配100K左右的內(nèi)存。所以這是一個很大的挑戰(zhàn)。

在手機(jī)使用中存在一些挑戰(zhàn),其中之一是關(guān)于麥克風(fēng)的問題。很多人打游戲時會在兩端握著這個手機(jī),這會把麥克風(fēng)堵住。如果在打游戲的同時還需要與隊友通信,但麥克風(fēng)被堵住了,對方就無法聽到聲音。因此,我們就會面臨一些挑戰(zhàn),比如如何解決麥克風(fēng)被堵住的問題。
在2020年,小米普及了立體聲功能的手機(jī),手機(jī)兩端都有speaker的聲音,所以聲音和麥克風(fēng)的距離非常近。這種近距離使信回比非常低,甚至可以達(dá)到-30dB的超低信回比。
在測試中,我們還遇到了一些超級混響環(huán)境下的自適應(yīng)回聲消除(AEC)問題。測試團(tuán)隊會拿著手機(jī)在封閉的玻璃房間里進(jìn)行電話測試,這種環(huán)境下存在非常強(qiáng)的混響。這種反復(fù)的聲音反射可能會導(dǎo)致濾波器收斂困難,給我們帶來一定的挑戰(zhàn)。

在實際應(yīng)用中,我們面臨一些問題。例如,無線充電器的使用,當(dāng)手機(jī)放在無線充電器上并打免提電話時,充電器的底部可能會堵住麥克風(fēng)。因此,這時需要算法智能性地解決這個問題。
另外,耳機(jī)的使用也可能遇到類似的問題,例如不正確的佩戴方式會導(dǎo)致陣列算法的出現(xiàn)問題。為此,我們采用自適應(yīng)波形形成而不是固定波束形成的方法。
除此之外,我們還面臨其他挑戰(zhàn),例如風(fēng)噪的處理,因為風(fēng)噪對麥克風(fēng)信號的影響是無規(guī)律的。因此,處理風(fēng)噪也是一個相對困難的問題。

在處理音頻的過程中,我們還遇到了一些挑戰(zhàn)。例如,在使用3G網(wǎng)絡(luò)時,如果用戶使用電信號碼,那么在3G網(wǎng)絡(luò)中可能會產(chǎn)生Tap噪聲,這是我們需要解決的問題之一。
另外,在早期的手機(jī)中,通常會有收音功能。然而,電路的GND地線可能會引入一些噪聲,這也需要我們處理。
-04-
通話降噪算法的落地實踐
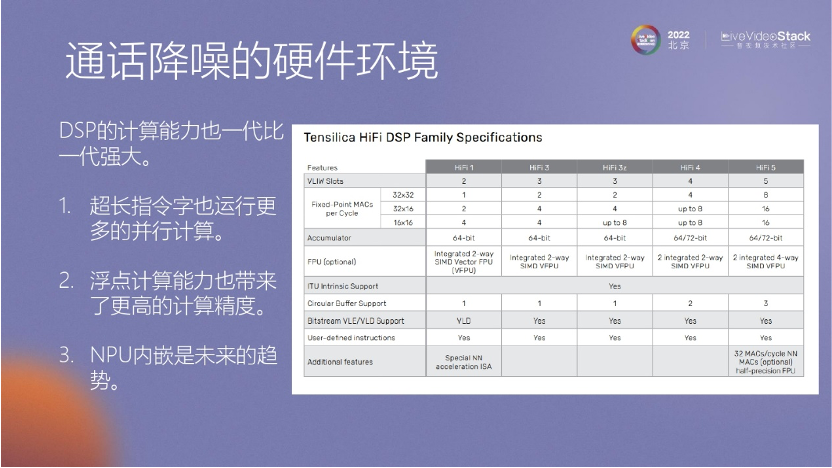
在處理計算量的問題時,芯片的發(fā)展起到了重要的作用,如MTK和展訊,都在開發(fā)內(nèi)核。這些內(nèi)核不斷升級,包括內(nèi)核數(shù)目和SIMD等功能也在不斷提升。SIMD指令能夠執(zhí)行多個乘加任務(wù),從而為我們提供更多的計算資源。
所以大家可以考慮一下算法芯片話的開發(fā),這是一個比較有潛力的平臺。未來,在計算能力上面也可以看到一代、二代、三代不停的成長。
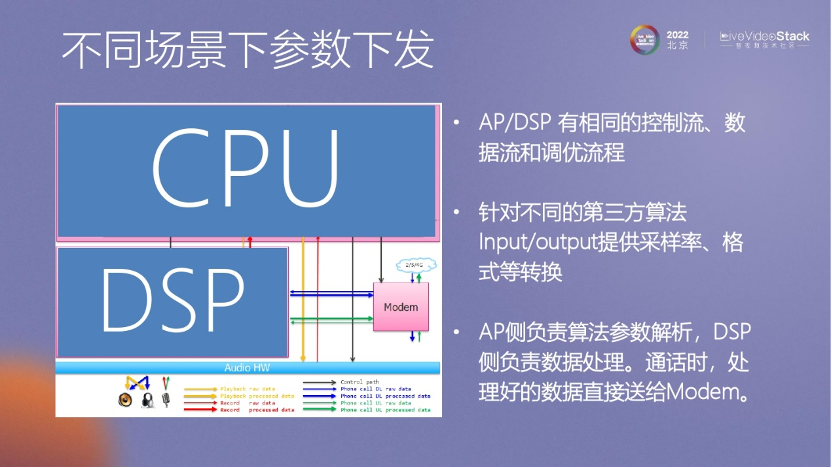
在將算法落地時,我們遇到的第二個問題是參數(shù)傳遞和更新的挑戰(zhàn)。算法是有一些參數(shù)的,我們需要將這些參數(shù)順利地傳遞給下層的DSP,以便更新算法參數(shù)。
我們遇到了一個耳機(jī)沒有聲音的問題。我們發(fā)現(xiàn)在測試時,沒有測試到印度耳機(jī)的例子,我們只使用國內(nèi)的耳機(jī)進(jìn)行測試,而印度耳機(jī)的增益非常小。所以一旦出現(xiàn)問題,我們必須迅速解決。
因此,我們的算法一旦調(diào)整完畢,就需要立即更新參數(shù)。在這種情況下,設(shè)計的結(jié)構(gòu)要求CPU能夠快速將參數(shù)傳遞給DSP,以便迅速解決問題。這里提到的Orasis架構(gòu)可以確保CPU與底層DSP之間實現(xiàn)快速通信。然而,我們也面臨一些問題。例如,在通話過程中,客戶可能抱怨通話質(zhì)量不佳,但無法獲得客戶的隱私數(shù)據(jù),所以我們會在客戶自己的手機(jī)上保存一些數(shù)據(jù)。
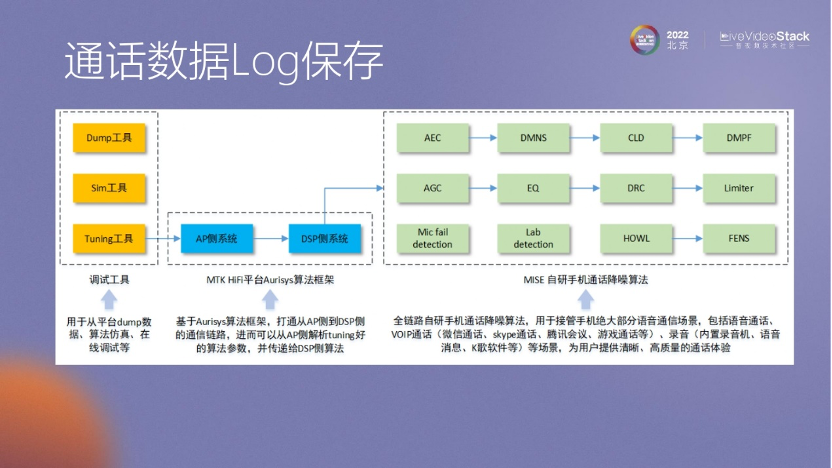
當(dāng)用戶反饋通話質(zhì)量不好時,可以保存相關(guān)的數(shù)據(jù)Log。我們會跟蹤這些日志,并直接與客戶溝通,詢問是否可以上傳這些日志。我們會在本地保留這些數(shù)據(jù),獲取部分用戶數(shù)據(jù)來做進(jìn)一步的數(shù)據(jù)分析。
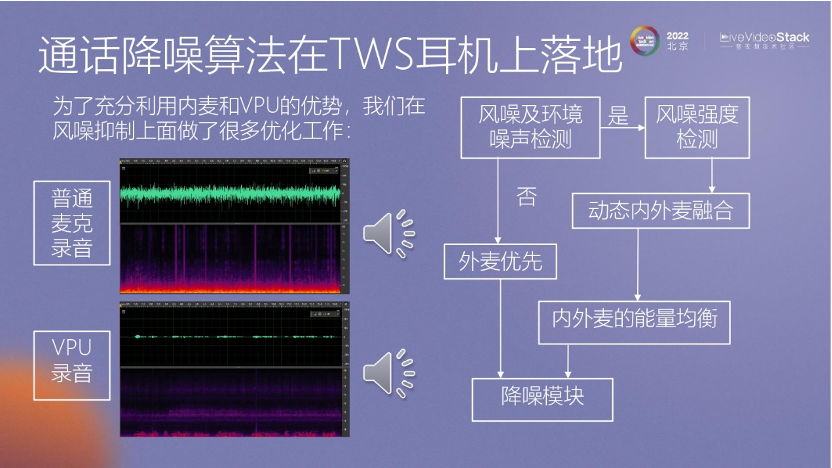
在 TWS耳機(jī)上,除了使用傳統(tǒng)的麥克風(fēng)進(jìn)行通信外,我們還可能使用 VPU進(jìn)行通信。在耳機(jī)上,VPU的數(shù)據(jù)處理能力會被充分利用。

我們會發(fā)現(xiàn)VPU的質(zhì)量并不理想,尤其是在高頻方面存在污染。然而,它在低頻方面的效果很好。為了解決這個問題,我們在這方面做了大量工作,把風(fēng)噪處理得非常平穩(wěn)。
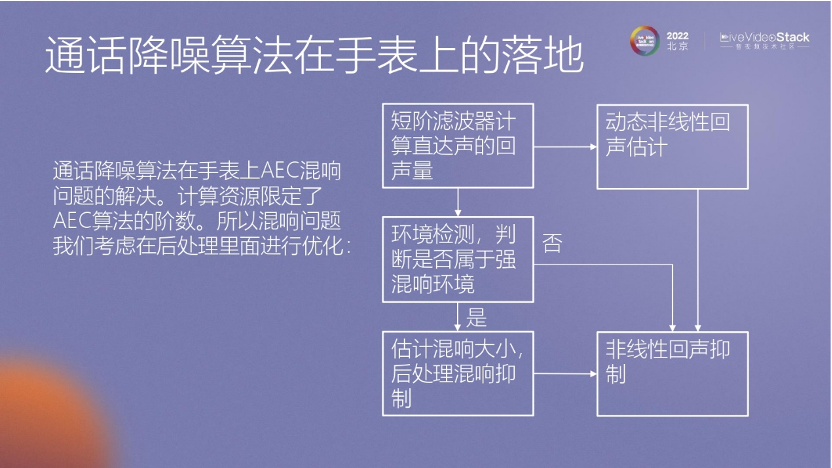
在手表上也做了這種處理,比如怎么抑制混響。
在手機(jī)通話方面,也進(jìn)行了一些處理,例如,只有手機(jī)的所有者能夠拿起手機(jī)進(jìn)行通話,其他人無法使用手機(jī)進(jìn)行通話。
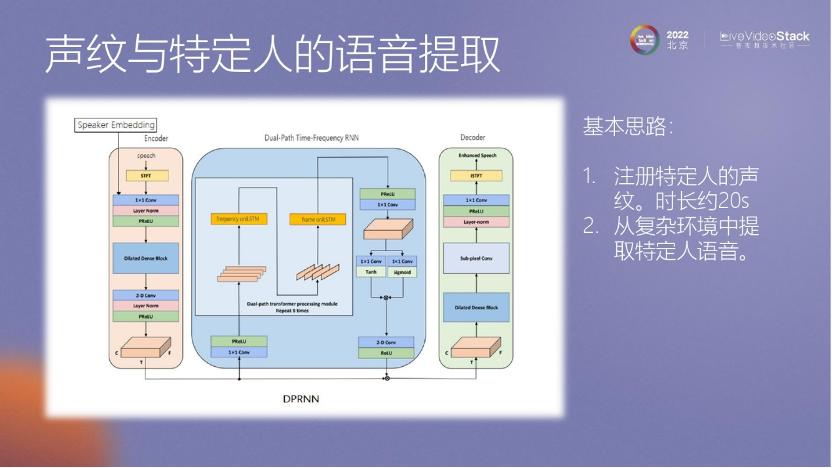
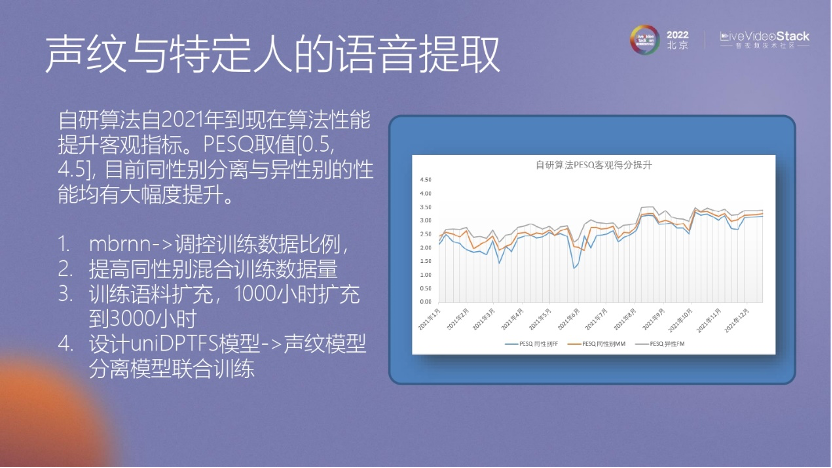
我們通過聲紋降噪的方法,利用前30秒或10秒甚至更短的數(shù)據(jù)來獲取用戶的聲紋信息。然后,在通話過程中,將應(yīng)用這個聲紋信息來進(jìn)行算法處理,以便抑制其他人的聲音。
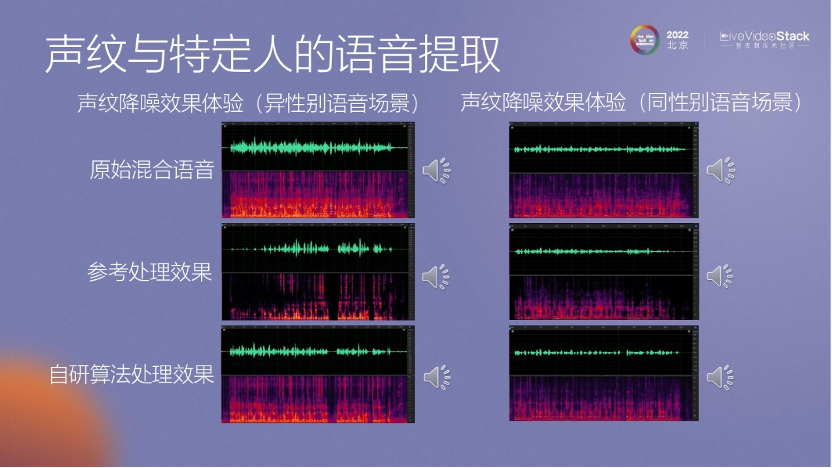
這是一些聲紋降噪效果體驗的演示。

通話降噪其實還有很多問題,我簡單羅列一下。例如強(qiáng)非線性情況下的一些問題、內(nèi)麥回聲的問題等,這都是需要解決的。
-05-
通話降噪的未來展望

未來展望方面,對于手機(jī)通話降噪,我們可以考慮基于低復(fù)雜度和低功耗的要求。這意味著可以結(jié)合傳統(tǒng)算法和深度學(xué)習(xí)技術(shù)。在高計算資源的情況下,深度學(xué)習(xí)模型可能會成為主要的選擇,并采用多級優(yōu)化的方式來提高性能和效果。

在低功耗的情況下,我做了簡單的羅列。有些問題可以使用經(jīng)典算法來處理,而對于深度學(xué)習(xí)方面,可以考慮以下幾個方面:特征選擇、網(wǎng)絡(luò)結(jié)構(gòu)、Loss 函數(shù)。但在實際應(yīng)用中,可能會遇到小模型在圖像上的表現(xiàn)較好,但在聽覺感知上效果可能不理想的情況。

最后,我認(rèn)為多模態(tài)降噪也是未來的一個方向。我今天的分享就到這里,謝謝大家。

LiveVideoStackCon是每個多媒體技術(shù)人的舞臺,如果您在團(tuán)隊、公司中獨當(dāng)一面,在某一領(lǐng)域或技術(shù)擁有多年實踐,并熱衷于技術(shù)交流,歡迎申請成為LiveVideoStackCon的出品人/講師。
掃描下方二維碼,可查看講師申請條件、講師福利等信息。提交頁面中的表單完成講師申請。大會組委會將盡快對您的信息進(jìn)行審核,并與符合條件的優(yōu)秀候選人進(jìn)行溝通。
掃描上方二維碼
填寫講師申請表單
本文為澎湃號作者或機(jī)構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機(jī)構(gòu)觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發(fā)布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報業(yè)有限公司

