- +1
當見未萌|從莎士比亞的猴子看懂ChatGPT如何煉成
·讓一只猴子在打字機上隨機地按鍵,當按鍵時間達到無窮時,幾乎必然能夠打出任何給定的文字,比如莎士比亞的全套著作。但是,我們不知道什么時候才能完成,如何找到猴子打出來的結果。
·GPT-3學了全部的武林秘籍,又用吸星大法吸收了各種內力,但是不能融會貫通。ChatGPT就像是找到了一個方法,徹底把全部內力打通,各種武術都學會了,再有內力加持,就變成了無敵高手。
很多人說ChatGPT這樣的人工智能已經擁有真正的人類智慧。他們提到了許多例子,比如ChatGPT能夠和人類對話,甚至可以進行智能聊天,可以幫助你潤色文章、提取摘要,甚至直接幫你擴寫內容。但是事實并非如此。
首先,我們必須明確,人工智能并不是真正的智能。它是一種人造智能,是由人類通過研究和開發創造出來的。因此,它不具備真正的人類智慧,而只是一種模仿人類智慧的技術。
其次,雖然ChatGPT可以聊天,但這并不能證明它擁有真正的人類智慧。聊天只是一種表面現象,并不能說明ChatGPT擁有人類的思考能力。只有當ChatGPT能夠理解人類的思想,并能夠思考、判斷和決策時,我們才能說它擁有真正的人類智慧。
最后,人工智能是一個極具挑戰性的領域。盡管科學家和工程師們已經取得了巨大的進步,但人工智能還有很長的路要走。我們不能因為當前的技術水平而把人工智能誤認為是真正的智慧,應該保持理性的態度。
但是,也不能因為ChatGPT不是完全跟人腦一樣的智慧體就小瞧它,它可以在很多方面輔助我們。比如,它可以幫助我們解決一些復雜的數學問題,甚至可以幫助我們預測未來的發展趨勢。此外,它還可以用于智能客服、智能問答、智能聊天等多種應用場景。
今天,我們就好好聊聊ChatGPT的原理和細節,局限性以及應用場景。
我們盡量不用任何公式、數學模型來把問題搞復雜,對大眾來說,了解ChatGPT的原理可以滿足他們的好奇心,也利于他們用好ChatGPT,在合適的地方用,該怎么用。
首先,我簡單地引入一個莎士比亞的猴子的概念。
無限猴子定理
讓一只猴子在打字機上隨機地按鍵,當按鍵時間達到無窮時,幾乎必然能夠打出任何給定的文字,比如莎士比亞的全套著作。
這個定理有各種表述,也可以說,只要有足夠多的時間,足夠多的猴子,可以打出來整個大英圖書館或法國圖書館的全部藏書,等等。
這是在揭示隨機的信息里可能蘊含了無盡的信息。也有一個說法是,在圓周率π里包含了人類全部的信息,因為π是無限不循環小數。
但是,隨機信息和有信息量的信息的區別在于,即使我們知道猴子最終可以打出莎士比亞的全套著作,我們也不知道什么時候才能完成,如何找到猴子打出來的結果。
劉慈欣有一本小說,叫做《詩云》,大概邏輯是一個高于人類文明無數倍的外星生物,了解到人類有詩,看了無數人類的文學作品。它想超越人類的詩作者,就想到了一個辦法,去隨機生成無數的文字,在這些文字里面必然包含了無數的優秀的詩。但是最后,它發現,生成這些隨機的文字,存儲它們需要耗費無數資源。生成了也沒用,因為無法找到。
我引入這個隱喻就是想介紹,雖然GPT已經包含了智能,但是也包含很多問題,語言模型的先天問題。如何從一個貌似包含了人類全部文字信息的語言模型,引出一個可以穩定執行各種命令、回答人類各種問題的實用產品?這就有了GPT-3這樣的超級無敵AI機器,然后需要解決的問題,也就是我們今天為什么能看到ChatGPT的原因。
首先我們需要了解GPT和語言模型。
什么是語言模型
ChatGPT的本質是GPT-3,而GPT-3是一種語言模型,要理解ChatGPT和GTP-3,我們需要先理解什么是語言模型。
語言模型是一種人工智能模型,它可以對給定的語言文本進行分析和建模,并預測下一個可能出現的詞語。例如下圖:
最簡單的也是最早期的語言模型叫做N元模型,很簡單也很好理解。就是把句子里連續N個單詞(漢語的話連續N個漢字,或連續N個詞)當作一個單元,拆解以后,統計他們相鄰出現的概率。
比如,一個英文例句為, the students opened their books,用N元模型來分析:
·1元:“the”, “students”, “opened”, “their”, “books”
·2元:“the students”, “students opened”, “opened their”, “their books”
·3元:“the students opened”, “students opened their”, “opened their books”
·4元:“the students opened their”, “students opened their books”
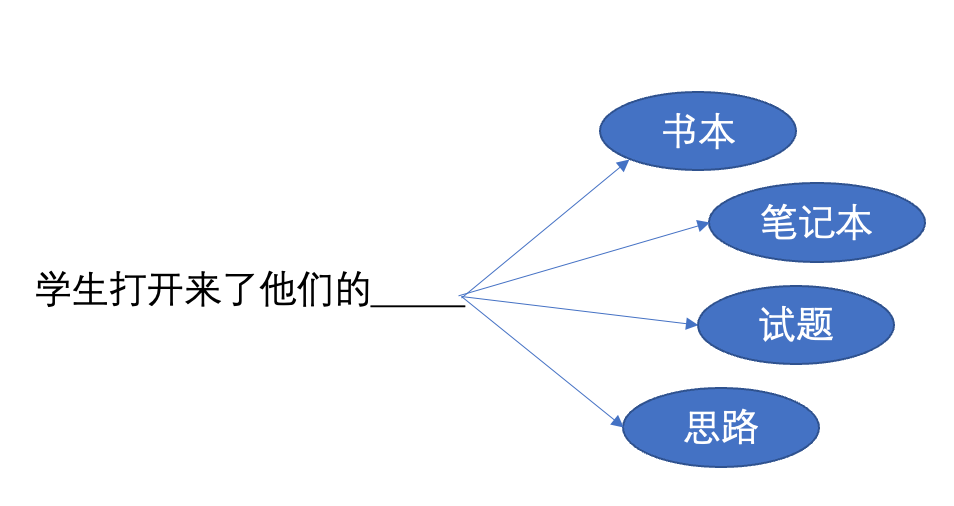
如果是一句中文:學生們打開來了他們的書。用N元模型來切分(已分詞):
·1元:“學生們”, “打開”, “來了”, “他們”, “的”, “書”
·2元:“學生們打開”, “打開來了”, “來了他們”, “他們的”, “的書”
·3元:“學生們打開來了”, “打開來了他們”, “來了他們的”, “他們的書”
·4元:“學生們打開來了他們”, “打開來了他們的”, “來了他們的書”
那么當問題是,“學生打開來了他們的______”時,我們到底應該選擇書本、筆記本、試題、還是思路呢?這就要看出現的概率了。
也就是,在給定的語料庫下,“學生打開來了他們的書本”,“學生打開來了他們的筆記本”,“學生打開來了他們的試題”和“學生打開來了他們的思路”跟“學生打開來了他們的”出現次數的比值關系了。
N元語言模型可以算作最簡單的語言模型,后面會介紹語言模型的一步步發展,但是它們的實現細節差異很大,但是基本上要完成的任務是一樣的。
語言模型本身就可以應用在很多地方,比如輸入法的聯想:
聊天和信息軟件的自動推薦:
Google搜索的自動推薦:
但是更重要的是,語言模型通常用于幫助構建其他的自然語言處理任務,如語音識別、機器翻譯、文本分類等,它可以幫助計算機理解和處理人類語言。語言模型可以通過預訓練和微調來實現模型的提升,并且在不斷推進的研究過程中也取得了巨大的進步。
語言模型的發展歷史
語言模型的發展可以追溯到20世紀50年代末,當時科學家們開始探索如何讓計算機處理人類語言。在隨后的幾十年里,隨著計算機硬件和軟件技術的發展,語言模型也不斷演進。20世紀90年代,神經網絡模型開始被廣泛應用于語言模型的研究,并取得了顯著進步。隨后,深度學習模型也開始在語言模型領域得到廣泛應用,并取得了更多的成果。
在歷史上,有許多重要的語言模型,其中包括:
·基于N元語法的語言模型:這是最早的語言模型之一,它基于N元語法的概率分布來建模語言文本,并預測下一個詞語的可能性。它的優點是簡單易行,但缺點是無法處理長距離依賴關系。
·神經網絡語言模型:這是一種基于神經網絡的語言模型,它通過多層感知器來建模語言文本,并使用語言模型的損失函數來訓練模型。它的優點是可以處理長距離依賴關系,但缺點是計算復雜度高,難以訓練大規模的模型。
·基于RNN(循環神經網絡)的語言模型:這是一種基于循環神經網絡的語言模型,它通過對時序數據進行處理,來捕捉語言文本中的長距離依賴關系。它的優點是能夠處理長距離依賴關系,但缺點是計算復雜度高,難以處理長文本。
·基于Transformer的語言模型:這是一種基于Transformer模型的語言模型,它通過結合注意力機制和多頭注意力機制,來實現對語言文本的建模。它的優點是計算效率高,能夠處理長文本,并且可以通過預訓練來提高模型的泛化能力。它的缺點是訓練時需要大量的訓練數據,并且需要高性能的計算機硬件支持。
·基于BERT的語言模型:這是一種基于雙向注意力機制的語言模型,它通過對語言文本的上下文進行建模,來提高模型的表示能力。它的優點是能夠有效地捕捉語言文本中的上下文信息,并且可以通過預訓練來提高模型的泛化能力。它的缺點是訓練時需要大量的訓練數據,并且需要高性能的計算機硬件支持。
總的來說,語言模型的發展歷史可以分為三個階段:早期的基于N元語法的語言模型,中期的神經網絡語言模型和基于RNN的語言模型,以及近年來出現的基于Transformer和BERT的語言模型。這些模型在不同時期都取得了重要突破,為人工智能領域的發展做出了巨大貢獻。
GPT各個版本之前的差別和發展歷史
·GPT:這是最早的GPT模型,它采用了單層的Transformer模型,并通過對大量語言文本進行預訓練來提高模型的泛化能力。它可以用于各種自然語言處理任務,如文本生成、語言模型預測。通過對40億個語言文本詞語進行預訓練來提高模型的泛化能力。
·GPT-2:這是GPT模型的下一個版本,它采用了多層的Transformer模型,并通過對更大量的語言文本進行預訓練來提高模型的泛化能力。它具有更高的計算能力和更豐富的語言表示能力,可以用于更復雜的自然語言處理任務。通過對7000億個語言文本詞語進行預訓練來提高模型的泛化能力。
·GPT-3:這是GPT模型的最新版本,它采用了更多層的Transformer模型,并通過對更大規模的語言文本進行預訓練來提高模型的泛化能力。它具有更高的計算能力和更豐富的語言表示能力,可以用于更多種類的自然語言處理任務,如文本生成、語言模型預測、機器翻譯、問答系統等。通過對175000億個語言文本詞語進行預訓練來提高模型的泛化能力。
·ChatGPT:ChatGPT是一種專門用于實現對話系統的自然語言處理模型,它采用了多層的Transformer模型,并通過對大量對話文本進行預訓練來提高模型的泛化能力。可以說ChatGPT是GPT-3的一個特殊應用,它專注于對話系統領域,而GPT-3則是一個更加通用的自然語言處理模型,可以應用于更多種類的自然語言處理任務。
GPT-3的語料包含哪些內容
具體來說,GPT-3的語料包含了以下內容:
·豐富的語言文本:GPT-3的語料包含了大量語言文本,包括小說、新聞、網頁、博客、社交媒體等各種類型的文本。這些文本來自于不同的語言、文化背景,并且涵蓋了廣泛的話題。
·多樣化的語言表示:GPT-3的語料涵蓋了多種語言表示方法,包括文本、圖像、音頻、視頻等多種形式。這使得GPT-3模型能夠捕捉到不同類型的語言信息,并實現更為豐富的語言表示能力。
·深度的語言理解:GPT-3的語料還包含了大量的語言理解信息,如語義、句法、語用等。這使得GPT-3模型能夠更深入地理解語言文本的含義,并能夠更準確地完成各種自然語言處理任務。
總的來說,GPT-3的語料包含了豐富、多樣化和深度的語言信息。
這么厲害的ChatGPT到底是不是真的達到了人類的智慧?
ChatGPT可以幫你寫文章,可以幫你起標題、潤色文章、擴寫文章、提取摘要、校對文字,還可以翻譯。它還可以幫我們寫程序,查詢函數的參數、進行代碼審核、寫unit test,等等。它還可以幫我們學英語,找例句、翻譯、潤色英文作文,等等。
它做的甚至比一些專門設計去做這些工作的軟件還好,甚至可以達到比較厲害的人的水平,那么它就真的擁有智能了嗎?
其實并不能。
舉一個例子,我們問ChatGPT,1+1等于多少?
它會回答:

很多人做過很多這樣的加法測試,都得到了正確的結果,例如,34+56等于多少?
它回答:

答案是對的,看起來也頭頭是道,但是“將結果相加得到 10 + 8 = 18 ”這句話是什么意思?不符合我們的數學基本原理。
雖然最后的結果是對的。我們再隨便把數字加大,比如問它,70654+89034等于多少?
它回答道:

我們一眼就發現結果也是錯了,論述也是錯誤的,但是為啥聽上去,還是頭頭是道呢?
首先,它的語料庫包羅萬象,一些數學題、簡單的加減乘除的教材可能也有,所以,當一個題目的答案在它的語料庫里時,它多半回答正確。這個過程就類似于它去自己的數據庫里查了一次一樣(實際上是因為整理過的語料里,正確結果存在的概率一定高于錯誤結果)。
但是當數字很大、很怪,大概率語料庫中不存在的時候,它所輸出的加法的結果就是基于語言學邏輯概率的結果,而不是數學邏輯下的結果,自然就有可能大錯特錯了。但是它仍舊可以給你講得頭頭是道。
你可以理解為它是一個自然語言學問的博士,對語言無比精通,對其他知識一無所知,天天跟各種數學家交談(在數學語料下訓練),它聽過的東西,一般不會答錯,雖然它并不明白它回答的意思是什么。它的泛化能力很強大,讓你以為它可以舉一反三,但是這種泛化是基于語言結構和語料的,并不能無中生有,不能進行嚴密的邏輯推理。所以,它沒聽過的東西,它回答的時候近似于胡猜。但是聽起來很有道理,因為它很會說話,所以,有很多時候可以蒙對。
所以,因為它的語料庫、知識庫包羅萬象,所以你問一些包含在知識庫、語料庫內的內容,它幾乎都不會答錯。它似乎是一個全能全知的神。但是它其實并不理解這些內容。
當然,我們現在說的是ChatGPT,它可以做無數事情,但不是每件事情。它不是真的學會了數學。但是ChatGPT比GPT-3的效果要好得多。所以,GPT-3推出時引發了無數業界的關注,但是普通人并不了解。只有ChatGPT出現以后,GPT家族才成了徹底的顯學。
其實,我前面講了,GPT只是一個語言模型,它確實可以補全很多話,很多時候會表現得非常有智能。但是很多時候,它會輸出車轱轆話,會輸出毫無意義的話,有時候結果又很好。它在真正被使用前,往往需要公司進行finetune。所謂finetune就是使用針對性的語料對GPT-3進行針對性的訓練,在finetune的過程中,GPT-3原來包含的語料信息和知識信息不會消失,但是會形成對特定問題的特定領域的知識。
比如Notion AI和Craft AI都是把GPT-3用在筆記應用里,它們就對GPT-3在文本潤色、標題處理、摘要等具體應用方準備大量的語言,去finetune,從而讓GPT-3的輸出效果在筆記應用這個層面更好用。
這就有點像我們的莎士比亞猴子,本來空讀了無數的書,但是不知道人們喜歡它怎么說話,所以說話完全由著性子,雖然飽讀詩書,但是看起來還是不夠聰明。經過了finetune,它知道了在某個地方大家喜歡怎么說話,它就學著這么說話,就讓大家覺得聰明了。

讓一只猴子在打字機上隨機地按鍵,當按鍵時間達到無窮時,幾乎必然能夠打出任何給定的文字,比如莎士比亞的全套著作。
或者用一個金庸小說里的橋段,GPT-3學了全部的武林秘籍,又用吸星大法吸收了各種內力,但是不能融會貫通。有時候打出一拳來威力無窮,有時候又軟綿無力,不能收放自如。然而這時候,如果學了一門劍法,劍術加內力就成了劍術高手。
但是,ChatGPT不是簡單的在任何方向上單獨finetune的結果,我會詳細介紹,為什么ChatGPT在無數領域都可以做出很好的效果。
ChatGPT就像是找到了一個方法,徹底把全部內力打通,各種武術都學會了,再有內力加持,就變成了無敵高手。
WebGPT和Google
首先我們介紹一個OpenAI沒有正式發布的產品WebGPT。
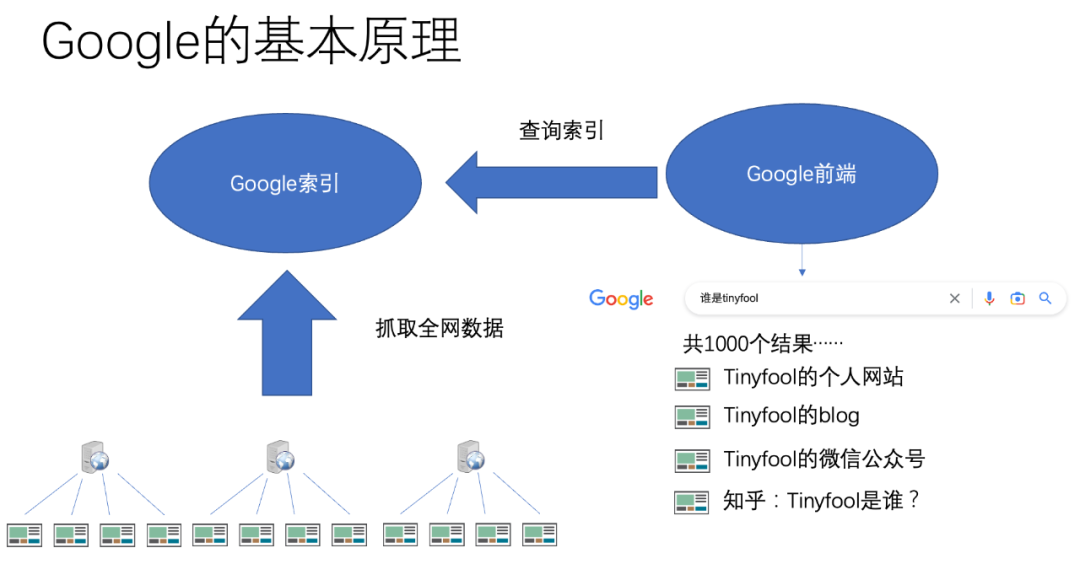
我們知道Google的原理,Google的本質就是抓遍全網的數據,然后建立索引。所謂一個關鍵詞的索引,其實就是一個關鍵詞的全部結果的列表。如果你搜一個復雜的問題,就等于是把多個關鍵詞的索引組合起來得到一個結果。
你不管問什么問題,Google本質上就回答有xxx個答案,然而按照相關性排序,最靠譜的排在前面。
Google的基本原理:
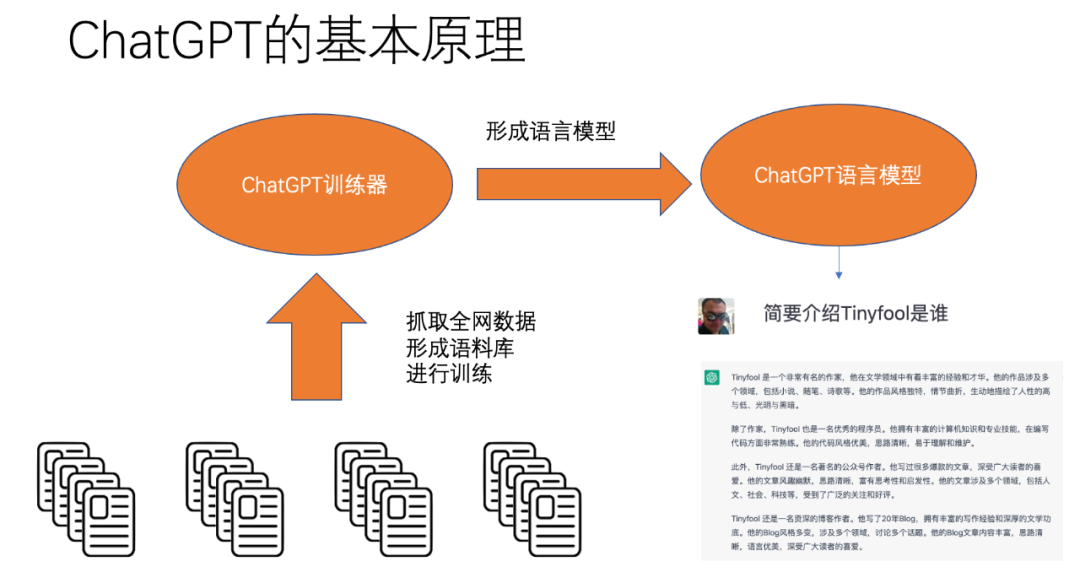
再看ChatGPT的基本原理:
時效性
從時效性來看Google更好,任何信息發布后幾天,甚至幾分鐘內,在Google里就可以搜索到。這是因為Google的爬蟲每時每刻都在爬取新的內容,而Google的索引服務也每時每刻都在更新索引。
而從GPT來看,ChatGPT是最近推出的,包含了很多新的內容,但是也只是截止到2021年而已,比如我問它,2022年8月發生了什么大事兒,它回答:

但是,我問它,2021年12月發生了什么大事兒,它回答:

抓取數據后,編入語料庫,需要進行大量的處理,包含數據清洗、對齊和一些語義挖掘,所以需要大量時間。而海量語料庫的訓練也需要海量的計算資源和時間,目前還無法像Google那么隨時更新。
所以,GPT發布于2018年,GPT-2發布于2019年,而GTP-3發布于2020年。ChatGPT最近發布,但是數據可能截止到2021年底左右。
那什么是WebGPT呢?
WebGPT演示。
所謂WebGPT是OpenAI沒有正式發布的一個產品,僅僅是一個Demo(展示)。它的思路是從Google的搜索結果里面找到最好的內容,然后整合成一篇短文。你可以理解為,比如它可以把Google搜索一個關鍵詞的前十名文章湊成一篇長文,然后用它自己的摘要功能把這篇超長的文章寫成一個比較短的摘要。
ChatGPT是怎么煉成的呢?
前面介紹了語言模型,GPT-3,甚至WebGPT,是希望大家建立一個概念。在ChatGPT前,GPT-3已經表現出了智能,但是結果不穩定,使用之前需要針對應用領域finetune。但是ChatGPT幾乎什么都能干,它是怎么煉成的呢?
簡單地說,三個步驟:
·收集示例數據,訓練一個有監督的模型
·收集比較數據,訓練一個獎勵模型
·根據獎勵模型,對有監督模型進行持續的強化學習
1、收集示例數據,訓練一個有監督的模型

如上圖,第一步,系統從之前收集的提示數據庫,也就是一堆形形色色的問題,可能有幾萬到幾十萬的有意義的問題,中間選一個。
比如這個問題是:如何向一個六歲小孩兒解釋什么是登陸月球?
然后,由一個標注人員,就是一個人,來寫一個期待AI能回答出來的比較好的答案的范本。
這些問題和人寫好的回答,就形成了訓練數據。
用這些數據去finetune現有的GPT-3或GPT-3.5模型,得到一個監督學習的模型。這個模型的精神內核還是GPT,但是它更會回答問題了,它參考了這些數據庫里抽取的問題和標注人員寫好的答案。它具有了一定的好好回答問題的能力。
2、收集比較數據,訓練一個獎勵模型

如上圖,有了剛才第一個有監督的模型以后,我們就可以讓那個模型多次輸出不同的答案。然后讓標注人員對多個結果進行質量評估。比如得到D>C>A=B的結果。也就是A和B答案質量差不多,C更好,D最好的這么一個評估結果。這樣我們就可以給答案排序。
有了問題、一組答案和排序,就可以訓練一個獎勵模型。這個獎勵模型就是,給它任何一個問題和一組答案,它都能自動判斷哪一個答案更好。
3、根據獎勵模型,對有監督模型進行持續的強化學習

有了第一個回答問題的監督模型,評估答案的獎勵模型,就可以開始強化學習的循環。
所謂的強化學習就有點像《射雕英雄傳》里周伯通的左右互搏,我們讓AI不斷生成答案,然后根據獎勵模型,我們可以告訴AI哪一次生成的答案更好。如果結果好,我們就鼓勵模型繼續這么做,如果不好,我們就懲罰模型讓它改進。
為什么會有這三個步驟呢?其實前面兩步都是監督學習。需要人工參與,需要準備大量的標注數據。這樣訓練的規模很難上去,經濟成本和時間成本都很高。第三步,有了前兩步的準備,就全部是機器左右互搏,就不再需要人工的參與,就可以進行海量運算,去不斷優化結果了。
前兩步的數據量估計在幾萬到幾十萬量級,成本高昂,曠日持久。但是到了第三步,幾乎不需要人的參與,主要耗費的就是計算力和電力。這個時候,訓練的規模就可以幾乎無限大,盡力去追求最好的結果。
如果你了解圍棋天下第一的AlphaGo,其實它最早期的版本就是通過標注信息進行監督學習。在那個時期,它相當于接受了人類所有歷史上已知的棋局,就已經達到了秒殺全部人類高手的能力。但是那時候,相對于圍棋全部的知識來說,AlphaGo和人類還沒掌握到全部的精髓。

著名圍棋選手柯潔對戰AlphaGo。
后面的AlphaGo也是用強化學習去訓練的,這個時候,全世界的人類都無法跟AlphaGo比肩,人類的歷史棋譜也不如AlphaGo的水平高了。怎么繼續提高?就是左右互搏,兩個原始的AlphaGo互相下,沒有限制的各種下,探索人類從來沒有達到過的高度。用機器來判定每一步哪個AlphaGo下得更好,逐漸相互學習,得到了目前人類和機器都無法企及的高度。
ChatGPT的第三步也是如此。這也說明為什么目前ChatGPT雖然看起來萬能,但是它會主動說不掌握2021年12月以后的信息。因為訓練GPT-3和GPT-3.5已經是曠日持久的工作,需要幾個月時間,用大量最好的AI服務器不停訓練。而在GPT-3和GPT-3.5的基礎上,得到了前兩步的監督模型和獎勵模型后,進行強化學習還需要大量訓練時間去精益求精。
好。我們盡全力不用任何公式,用普通人應該能聽得懂的原理解釋方式去講清楚了ChatGPT是怎么煉成的。它當然還有局限性,但是它也仍舊在繼續進化中。
據說,GPT-4很快要發布,后續GPT家族,還有Google、Meta,其他硅谷巨頭的類似模型也都在研發,我們繼續關注AI如何改變我們的生活,我們怎么去理解AI的發展,從而了解原理,更好地知道它的局限性和功能,用好AI。
參考資料:
1.無限猴子定理
https://zh.wikipedia.org/wiki/%E7%84%A1%E9%99%90%E7%8C%B4%E5%AD%90%E5%AE%9A%E7%90%86
2.Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 6 – Language Models and RNNs
https://youtu.be/iWea12EAu6U
(作者郝培強,網名Tinyfool,自由職業(自媒體),資深(也就是老的意思)開發者。二八法則,是工業時代的邏輯;而在智能時代,則是2%/98%的邏輯。如何成為智能時代2%的受益者?“當見未萌”,讓我們加入浪潮吧。本專欄由計算機學界專業人士為澎湃科技讀者特供。)




- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

