- +1
陳天奇高贊文章:新一代深度學習編譯技術變革和展望
作者:陳天奇
陳天奇是機器學習領域著名的青年華人學者之一,本科畢業于上海交通大學ACM班,博士畢業于華盛頓大學計算機系,研究方向為大規模機器學習。在本文中,陳天奇回答了目前深度學習編譯技術的瓶頸在哪里,下一代技術是什么?
2021年12月16日,第四次TVMCon如期在線舉行。從大約四年多前行業的起點開始,深度學習編譯技術也從初期萌芽階段到了現在行業廣泛參與的狀況。我們也看到了許多關于編譯和優化技術有趣的討論。深度學習編譯技術生態的蓬勃發展也使得我們有了許多新的思考。TVM作為最早打通的深度學習編譯技術框架已經可以給大家提供不少價值。但是就好像深度學習框架本身會經歷從從第一代(caffe)到下兩代(TF, pytorch)的變化一樣,我們非常清楚深度學習編譯技術本身也需要經歷幾代的演化。因此從兩年前開始我們就開始問這樣一個問題:“目前深度學習編譯技術的瓶頸在哪里,下一代技術是什么“。
比較幸運的是,作為最早打通編譯流程的架構我們可以比較早地直接觀察到只有嘗試整合才可以看到的經驗。而目前開始繁榮的生態本身 (MLIR的各種dialects,XLA, ONNX, TorchScript) 也開始給我們不少可以學習參考的目標。本文是對過去兩年全面深度學習編譯和硬件加速生態的總結思考,也是我們對于深度學習新一代編譯技術的技術展望,希望對大家有一些參考價值。本文的內容大部分來自于今年我們在TVMCon的主題報告。
現狀是什么:當前深度學習編譯解決方案和瓶頸
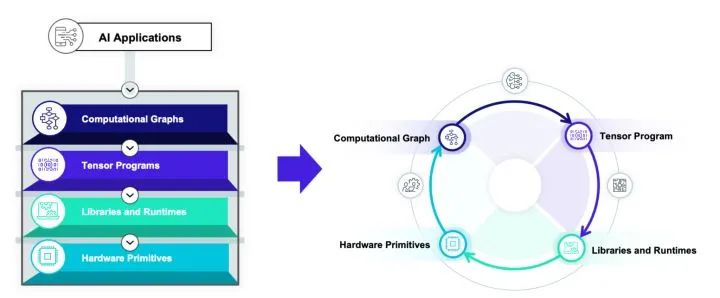
四類抽象
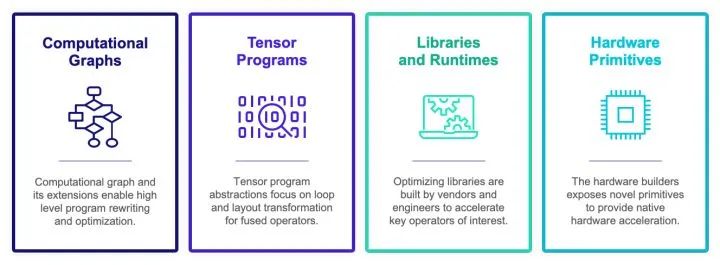
當然深度學習編譯加速生態已經從萌芽階段到開始繁榮生長的階段。但是拋開具體實現而言,現在深度學習編譯生態圍繞著四類抽象展開:
計算圖表示(computational graph):計算圖可以把深度學習程序表示成DAG,然后進行類似于算子融合,改寫,并行等高級優化。Relay, XLA, Torch-MLIR,ONXX 等基本都在這一級別。
張量程序表示(tensor program): 在這個級別我們需要對子圖進行循環優化,對于DSA支持還要包含張量化和內存搬移的優化。
算子庫和運行環境(library and runtime): 算子庫本身依然是我們快速引入專家輸入優化性能的方式。同時運行環境快速支持數據結構運行庫。
硬件專用指令 (hardware primitive) :專用硬件和可編程深度學習加速器也引入了我們專用硬件張量指令的需求。
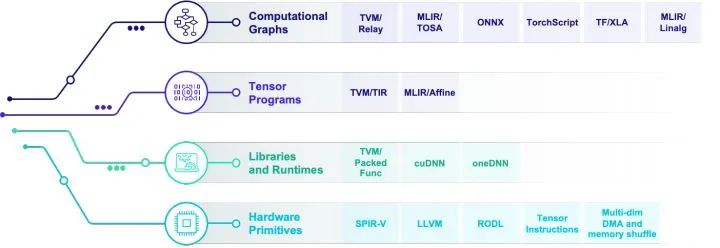
當然的深度學習編譯生態基本上也是圍繞著各種抽象的實現展開。上圖是對于當前生態的一個不完全總結。值得指出的是,算子庫和運行環境等本身未必直接和編譯技術相關。但是因為我們的目標是新硬件部署和運行加速,運行環境抽象和硬件指令也是生態的重要一環。
我們需要多層抽象本身基本是深度學習編譯和優化領域大家達成的一種共識。但是為了真正地支持機器學習,光依賴于各個組件本身是遠遠不夠的。我們發現最大的問題是“如何設計各個層級的抽象,并且對它們進行有效的整合”。
目前的解決方案
如果我們仔細地研究目前的整個生態,包括深度學習框架,編譯框架(包括基于MLIR,ONNX或者是TVM的解決方案)。大家都遵循一種叫做多層漸進優化(Multi-stage lowering)的方式。這種構建方式的大致思路是我們在每一層抽象中采用一個(有時多個)中間表示。我們會在每一個層級(dialect, abstraction)做一些內部優化,然后把問題丟給下一個層級繼續進行優化。
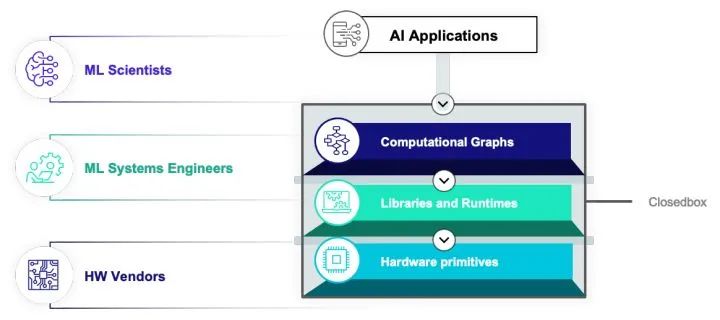
因為生態本身設計和其他一些原因,當然的解決方案基本有以下特點:每一個層級抽象基本由一個比較獨立的團體維護。層和層之間往往比較松耦合。最后解決方案本身往往是以一個黑盒工具的方式呈現給用戶。
很多人的一個愿景是只要每一層的優化做的好,把東西拼起來,我們就可以組合成一個滿足需求的解決方案。雖然這樣的做法的確可以達到一定的效果,但是我們也需要反問,multi-staging lowering真的可足以解決深度學習優化的問題嗎?
兩種隔閡
我們大約在三年前完成了基于multi-staging lowering的解決方案。當我們把全棧解決方案搭建起來并且不斷實踐之后我們發現有兩種隔閡阻礙整個行業的發展。
其中的第一種豎向隔閡阻隔了手工優化的方案和自動編譯優化的方案。如果我們看當前的深度學習運行框架和編譯框架。我們可以發現有兩種流派:一類是以手工算子優化為主的算子庫驅動方案。這一類方案一般可以比較容易地讓更多的優化專家加入,但是本身也會帶來比較多的工程開銷。另一類方案是以自動優化為主的編譯方案。編譯核心方案往往可以帶來更多的自動的效果,但是有時候也比較難以引入領域知識。大部分當前的框架基本都只為兩者中的其中一個設計。而我們往往發現實際比較好的解決方案其實同時需要機器學習工程師的輸入和自動化。并且隨著領域的發展,最優的解決方案也會發生變化。怎么樣打破這樣的豎向墻,讓手工優化,機器學習優化專家的知識和自動優化做有機整合,也是目前行業面臨的一個大的問題。
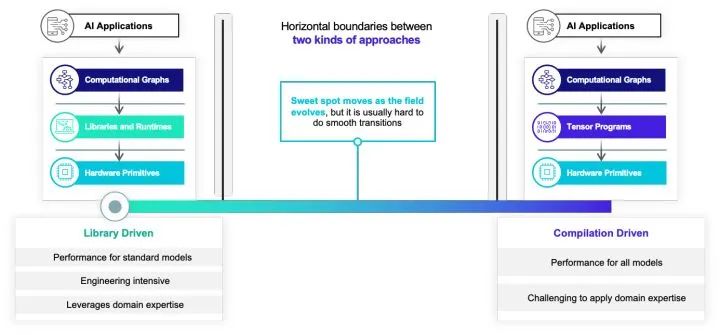
除了豎向高墻之外,第二類隔閡則一定程度上和multi-stage lowering的生態直接相關。因為我們往往會把不同層級的抽象分開來設計,雖然在抽象內部可以做比較靈活的優化。但是在一個抽象到另外一個抽象的轉換時候往往需要通過translator或者lowering批量轉換。這樣導致了我們很多困難都開始集中在一類抽象和另外一類抽象的邊界上,這樣導致了如果我們想要在邊界上面做一些分步的優化(如把其中一部分子圖交給一類編譯邏輯,剩下的交給其他編譯如邏輯)我們就必須在邊界上面引入大量的工程。另外一個常見的現象是這類轉換往往是單向的,我們一般會在高階的抽象如計算圖上面做一些優化,然后傳遞給張量計算層級。但是張量計算或者硬件層級的信息往往難以反饋給更高的層級。舉個例子,其實很多時候張量程序的優化本身可以反過來指導計算圖層級的算子融合和數據排布,但是當前的單向架構比較難自然地利用這一類反饋。
總結一下我們的經驗。深度學習編譯和優化本身不是一個一個層級可以全部完成優化的問題。解決相關問題需要各個層級抽象之間的聯動。隨著TVM和MLIR一類基礎架構的出現,我們其實已經可以比較容易地搭建出某一個層級的抽象或者dialect并且讓它們之間通過multi-stage lowering的方式從高到地級抽象進行逐層變換和轉換。但是現在的困難點往往出現在抽象的轉換邊界上。不論是在邊界引入更多的可模塊化整合變換,或者是進行嘗試反饋迭代,multi-stage lowering本身是遠遠不夠的。不僅如此,隨著抽象層級的增加,如果希望加入自定義算子,我們往往需要針對每個抽象層級進行進一步的架構,其中的開銷變得更加龐大。
因為各個抽象之間的豎向和橫向隔閡。不論我們如何做好一層抽象內部本身,我們依然難以做好端到端的整體優化。需要注意的是,這些隔閡和問題的存在和基礎架構的選擇無關,不論是基于MLIR,ONNX或者是TVM的方案,一旦采用了multi-stage lowering都會不可避免地面對這個問題。相信在領域里面努力的小伙伴不管采取什么基礎架構,在把方案打通之后或多或少都會碰到這個本質的問題。
未來在哪里:從箭頭到圈
這一節我們會介紹對于這一個問題經過兩年多總結的思考。這也是我們演化到新一代深度學習編譯系統的核心技術路線,我們把這一路線叫做TVM Unity。
我們可以注意到,幾乎所有的難點都由邊界隔閡產生,因此我們需要解決的重點是抓住關鍵點,消除邊界隔閡。我們的目標是把一個單向箭頭的multi-stage lowering方案,演化成一個可以讓各個抽象之間有機交互的一個圈。
整個技術路線總結下來包含三大關鍵點:
Unify: 統一多層抽象
Interact: 交互開放迭代
Automate: 自動優化整合
Unify: 統一多層抽象
為了打破抽象直接隔閡,我們需要完成的第一步是統一抽象。這當然并不意味著我們需要設計一個唯一的層級來解決所有問題 – 架構上面稍有不慎,我們可能會設計出一個整合了所有抽象短板的復雜表示。在這里我們依然需要承認每一類抽象的重要性,但是我們需要在不同類別的抽象之間進行協同設計,并且可以讓每一個層級和其它層級進行相互交互。
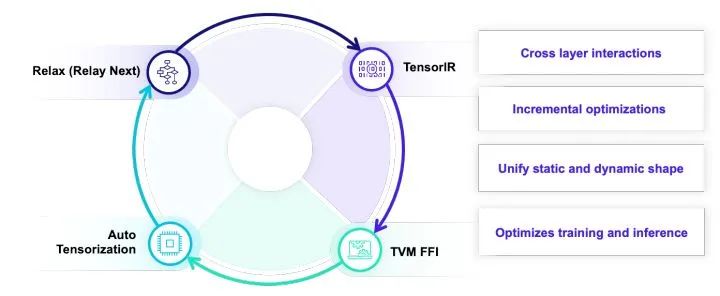
具體到TVM而言,TVM主要的重點放在四個抽象上。AutoTensorization用來解決硬件指令生命和張量程序對接,TVM FFI(PackedFunc)機制使得我們可以靈活地引入任意的算子庫和運行庫函數并且在各個編譯模塊和自定義模塊里面相互調用。TensorIR負責張量級別程序和硬件張量指令的整合。Relax (Relax Next) 會引入relay的進一步迭代,直接引入first class symbolic shape的支持。但是就和一開始提到的一樣,這里的關鍵點并不只在各個抽象層級本身,而是抽象之間的相互交互和聯合優化。

以上這個程序樣例就展示了我們統一抽象的設計目標。這是一個通過TVMScript表示的IRModule。MyIRModule是包含了兩種函數。其中tir_mm是一個TensorIR級別的函數。新一代的TensorIR的設計目標是實現 張量程序和硬件專用指令之間的通過自動張量化的聯動。再看relax_func這個函數。其中有幾個關鍵點。R.call_dps((n, m), tir_mm, [x, w])是在計算圖級別直接對于TensorIR函數tir_mm的直接調用。并且我們通過特殊的調用形式使得張量程序依然以和圖算子一樣的方式出現在計算圖中。支持這一特性意味著計算圖需要和張量程序層級表示進行聯合設計,使得計算圖的優化可以利用張量程序層級的信息。最后 R.call_packed("custom_inplace_update", gv0) 允許計算圖直接和TVM FFI函數進行交互。
多層抽象之間的相互統一整合雖然帶來了更多的一些設計考慮,但是也帶來了解決隔閡之后的不少優勢。舉個例子,假設我們現在有一個快速的算子優化思路,在傳統的編譯流程中常見的做法是引入在每個層級引入新的改寫規則。但是在統一抽象下,我們可以直接引入一個pass把一個局部算子先改寫成call_packed調用一個手寫的外部算子。在確認性能合理的情況下再考慮如何把一個局部改寫變成更加自動化的方案。同樣我們也可以把手工算子和自動代碼生成的方案更加有機地整合在一起。最后,因為對于TensorIR程序的調用直接被表示再圖程序中,我們可以直接把對于TensorIR的改寫優化變成對于對應計算圖的調用改寫,使得張量級別變換的信息可以反饋到圖級別的變換中去。
最后,值得注意的是樣例中關于動態shape的支持采用了symbolic shape的方案。樣例中的(n, m)和(n * m)中的n和m貫穿整個程序。使得我們可以在編譯優化時利用這些更多的信息來做更多動態相關優化。并且關于symbolic表達式的支持也完美地和TensorIR層級的symbolic shape統一在了一起。這一特性也很大地體現和協同抽象設計的重要性。
Interact: 交互開放迭代
除了抽象的整合之外,一個非常重要的課題是如何讓不同的人之間進行相互協作。深度學習編譯優化是一個涉及到各種各樣工程師人群的領域。算法專家希望開發新的模型和自定義算子,機器學習系統工程師需要開發系統優化,硬件廠商需要迭代自己的硬件。每一類人都會變對不同層級的抽象。深度學習領域的繁榮很大程度地歸功于深度學習框架的開放生態。任何人都可以以python的方式編寫我們的模型并且把它們和其人寫的模塊進行整合。傳統的編譯器領域往往會一個更加封閉的方式呈現出來。在一個multi-stage lowering的架構下把框架搭好,然后提供一個命令行接口給用戶。
雖然一個美好的愿景是我們可以把每一個層級的抽象做好最好再,然后再把火箭的零件全部拼接起來。但是這樣的愿望往往是不現實的,實際的情況是每一層都還是會有自己的問題。如何通過系統工程的方式做好整合互補,并且可以讓不同的人群可以在一起相互快速合作迭代出新的解決方案才是我們需要考慮的問題。
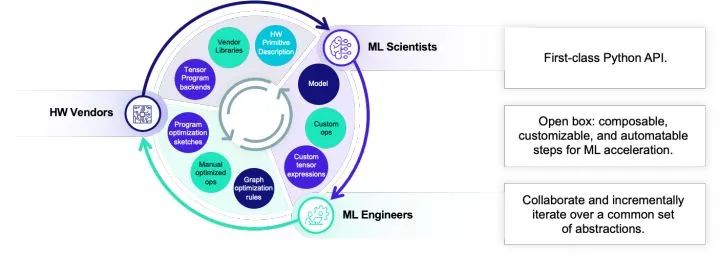
而這個時候允許不同的人之間進行協作,交互開發和迭代就是一個我們需要首要考慮的話題。在這個層面上,我們遵循以下幾點原則: python-first,通過TVMscript和直接多語言整合的架構讓大家都可以通過python API相互協作。開放開發不論是哪個抽象層級之間都可以整合交流。協作迭代,讓大家可以一起合作達到更好的效果。舉個例子,一個機器學習專家可以利用計算表達式來寫一個自定義算子,但這個自定義算子可以被系統專家寫的自動轉換規則優化,而其中自動轉換規則本身又利用的硬件廠商所提供的張量指令特性。當然這個整個鏈路的每一環都可以在一起快速聯動的時候,我們就可以快速地根據需求迭代出想要的解決方案。
Automate: 自動優化整合
自動優化始終是深度學習編譯器血液里面的東西,也是實現Unity的一個關鍵環節。
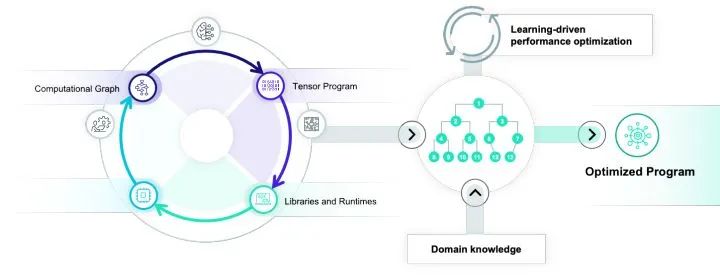
很多傳統的自動優化方案是排他的,也就是只有整個優化方案全部采用對應的模型的做法(如一些polyhedral model)才可以解決好,一旦嘗試引入領域知識,或者想要的優化跳出了原有的范疇,自動化就難以發揮優勢。我們需要改變這一觀點,重點思考如何在自動優化的過程中有效地整合領域專家知識。使得我們真正可以把自動化和高手之間的力量整合在一起。社區基于TensorIR的MetaSchedule正是往這個方向前進的重要一步。
整體生態整合
前面的幾節我們介紹了TVM Unity的三個關鍵技術點。當然unity本身設計的目標本身并不是解決所有問題。我們非常清楚只有當把這個圈和整個機器學習和硬件生態一起整合的時候我們才可以發揮最大的效率。而抽象的整合使得我們可以更加容易地提供更多種整合方式。我們可以通過子圖整合把TVM整合入已有的框架中,也可以把常見的硬件后端整合入TVM本身。統一的抽象可以使得這樣的整合以相對統一的方式發生在各個層級。
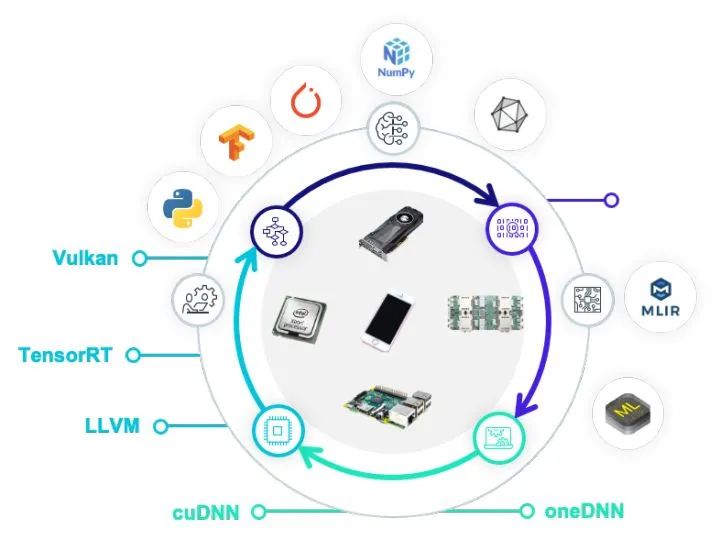
TVM FFI 等靈活的接口也讓我們可以和整個生態做靈活的對接。并且把不同的后端生態通過自動化做更加有效的整合。
總結和未來展望
這篇文章總結了我們對于深度學習編譯領域在過去兩年的思考和未來的展望。對于新一代架構的推動一直是我們核心關注的主題,這里提到的各個特性也都已經重構完成或者在進行中。TVM FFI在去年已經逐漸成熟,TensorIR本身剛被合并到主干,后續的metaschedule也會陸續進入主干。Relax本身也在社區進行開放開發。TVM Unity作為社區的核心主題也會是接下來一年的重點,并且在開發過程中的一些元素已經可以提供不少好處。當社區逐漸向這一技術方向靠攏對接,整合的優勢也會越來越明顯。
過去一年中常常看到一些關于深度學習編譯基礎架構的討論。其實從核心上面來看,基礎架構本身當然是重要的一環(scala之于spark一樣),不過不論MLIR, TVM或者其他編譯框架基礎架構本身也都在相互學習中趨近成熟。真正的瓶頸還是在于抽象的設計和更進一步真正地進行協同整合。當然其實三個技術關鍵點的選擇也的確影響了我們對于基礎架構的思考。比如TVM FFI作為比較重要的基礎架構支撐了交互和python-first的特性。
不論基礎架構,我們面對的真正問題是如何解決這些關鍵的隔閡問題,multi-stage lowering本身的缺陷導致了現有的方案必須有所突破才能演化到新一代的深度學習編譯系統。本文探討了這一演化的方向和具體的技術路線。希望可以對整個領域有所啟發。
在新一代的架構前進的道路上,我們不再是一個人在努力。很多的關鍵組件設計都是由各個同學一起合作完成。我們也歡迎更多的同學一起加入到社區中來,一起推動實現新一代深度學習編譯系統的共同建設中來。
原文鏈接:https://zhuanlan.zhihu.com/p/446935289?utm_source=wechat_session&utm_medium=social&s_r=0
蘇黎世聯邦理工DS3Lab:構建以數據為中心的機器學習系統
蘇黎世聯邦理工學院(ETH Zurich) DS3Lab實驗室由助理教授張策以及16名博士生和博士后組成,主要致力于兩大研究方向,Ease.ML項目:研究如何設計、管理、加速以數據為中心的機器學習開發、運行和運維流程,ZipML項目:面向新的軟硬件環境設計實現高效可擴展的機器學習系統。
12月15日-12月22日,來自蘇黎世聯邦理工學院DS3Lab實驗室的11位嘉賓將帶來6期分享:構建以數據為中心的機器學習系統,詳情如下:
? THE END
轉載請聯系本公眾號獲得授權
投稿或尋求報道:content@jiqizhixin.com:,。視頻小程序贊,輕點兩下取消贊在看,輕點兩下取消在看
原標題:《陳天奇高贊文章:新一代深度學習編譯技術變革和展望》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

