- +1
Deepmind最新成果:博弈論視角下的主成分分析
原創 Ian Gemp等 集智俱樂部 收錄于話題#復雜科學前沿202165個

導語
來自Deepmind 的論文“EigenGame: PCA as a Nash Equilibrium”獲得了ICLR2021年的杰出論文獎,該文通過多主體建模,用一個全新的視角,審視了數據降維中常用用的主成分分析法(PCA)。
Brian McWilliams、Ian Gemp、Claire Vernade | 作者
郭瑞東 | 譯者
趙雨亭 | 審校
鄧一雪 | 編輯
1. 從單主體智能到多主體建模
現代人工智能系統處理諸如識別圖像中的物體、預測蛋白質的3D結構這樣的任務,就像一個勤奮的學生準備考試一樣——通過對許多次的訓練,它們可以逐漸減少自己的錯誤率,直到取得成功。這是一項孤獨的努力,也是機器學習中通用的學習方式。
人類的學習是通過與他人互動與玩耍來進行的。一個人獨自解決極其復雜的問題是很少見的。通過讓求解問題具備類似游戲的互動性, DeepMind 已經成功訓練了人工智能進行 Capture the Flag 游戲,并在星際爭霸中達到人類大師的水平。這使研究人員想知道,以博弈論的視角看待模型,可否幫助解決其他基本的機器學習問題。
主成分分析(Principal Component Analysis,PCA)于20世紀初期被提出,是高維數據處理流程中的第一步:通過數據聚類,讓數據降維和可視化變得容易;同時也使得在分類及回歸任務中,學到數據的低維表征成為可能。在 Deepmind 的論文中,研究人員將主成分分析重新表述為一個競爭性的多主體博弈,將其稱為特征值游戲(EigenGame)。
主成分分析通常被表述為一個最優化問題(或單主體問題)。然而,該文提出,多主題建模帶來了新的洞察力和算法:利用最新的計算資源。這使主成分分析能夠擴展到以前需要太多計算資源的大規模數據集,并為未來的探索提供了一種替代方法。
最初的主成分分析,是由紙和筆完成的,之后轉移到數據倉庫的計算中心。但隨著數據集的增大,這種常見的計算方法已成為計算瓶頸。研究人員已探索使用諸如引入隨機化等方式,來改進大數據集上 PCA算法的性能。然而,這些方法,研究者發現其無法利用為深度學習準備的硬件資源,例如大規模并行的GPU和TPU。
PCA 與許多重要的機器學習和工程問題,都需要共同的解決方案,即奇異值分解(singular value decomposition)。通過以正確的方式解決 PCA 問題,該文提出的算法可以更廣泛地應用于機器學習樹的各個分支。

圖1. 一系列的機器學習任務,例如 PCA、最小二乘法、 譜聚類(Spectral Clustering)、潛在語義索引(Latent Semantic Indexing LSI)和排序都需要 SVD為其基礎。
例如,通過提取特征值,可以在社交網絡上進行譜聚類,如下圖所示,圖像展示了根據多主體建模找到的特征向量,經過 K-means算法得出的對臉書界面的聚類可視化,其中不同顏色代表真實的分類標簽,不同的花瓣代表聚類得出的結果。結果顯示聚類結果中7/8的標簽都能對應到真實標簽。
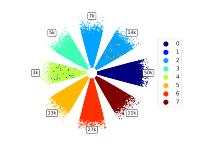
圖2. 臉書頁面通過特征值游戲聚類的可視化,來源:EigenGame Unloaded When playing games is better than optimizing Fig 7
2. 特征值游戲 EigenGame 的規則
和任何棋類游戲一樣,為了將 PCA 重新定義為一種游戲,研究人員需要一系列的規則和目標供玩家遵循。有許多可能的方法來設計這樣一個博弈;然而,關鍵的思路來自主成分分析本身:最佳解決方案由特征向量組成,這些特征向量捕捉數據中,方差最大并且彼此正交的維度。

圖3. 該游戲中,每個玩家都希望對齊方向的差異最大(即更大的數據傳播),但也需要保持與相對其編號較低的玩家呈正交垂直。
在特征值游戲中,每個玩家控制一個特征向量。玩家通過解釋數據中的差異來提高他們的得分,但是如果他們與其他玩家太接近,就會受到處罰。該游戲還建立了一個層次結構:玩家1只關心方差的最大化,而其他玩家則不得不同時擔心最大化他們可解釋的方差,并最小化與編號比自己低的玩家的相似度。這種獎勵和懲罰的組合決定了每個玩家獲得的收益函數。
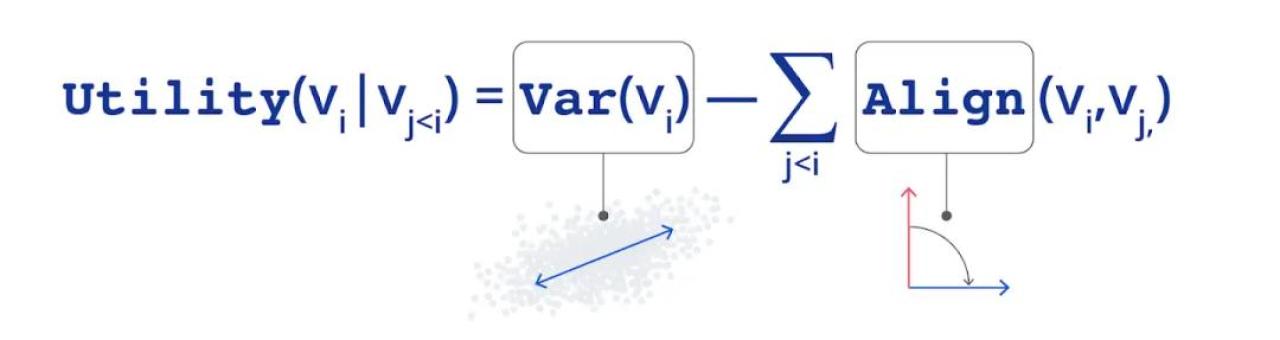
圖4. 玩家參與特征值游戲的收益計算法示意圖
通過經過適當設計的方差(var)和對齊(align)項,該論文證明了:
1)如果所有的玩家都表現最優,他們等價于一起實現了游戲的納什均衡點,而這就是 PCA 算法的解決方案。
2)如果每個玩家獨立地使用梯度上升法,最大化他們的效用,那最優點是有可能實現的。

圖5. 特征值游戲引導每個玩家沿著單位球面從空的圓圈走向平行的箭頭(代表找到的特征向量)。藍色代表玩家1。紅色代表玩家2。綠色代表玩家3。
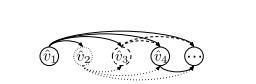
圖6. 每個玩家 i 的效用函數取決于編號比TA小的玩家,這里用有向無環圖來表示。每個編號更低的玩家必須以固定的順序比對其它玩家傳播它的當前向量。(來源:EigenGame: PCA as a Nash Equilibrium)
算法中,玩家能夠同時獨立地進行梯度上升,這一特性尤其重要,因為它允許讓計算分布在幾十個谷歌云的TPU上,從而實現了數據和模型的并行計算。這使得該文提出的算法能夠適應真正的海量數據。特征值游戲能在數小時內為包含數百萬特性或數十億行的數據集找到主成分。

圖7. 特征值游戲并行運算示意圖:每個有色方塊都是一個獨立的主體。首先,每個主體在一個設備上計算更新;之后每個主體被復制到多個設備,并使用獨立的批次數據計算更新;然后對被復制后的不同主體進行平均,以形成一個更健壯的更新方向。
3. 多智能主體,從優化到赫布法則
通過從多智能主體的角度審視 PCA,該文對可擴展到大數據集的算法進行了新穎的分析。該文還發現了一個與赫布法則(Hebbian Learning ,神經元在學習時如何調整其連接權重)的令人驚訝的聯系。在特征值游戲中,每個玩家最大化他們的效用過程中,如何更新其特征,類似于赫布法則中,大腦具有可塑性的神經元的突觸,如何從周圍的環境習得規則。按照赫布法則,更新得出的連接會收斂到已知的 PCA 解決方案,但其中不會派生出任何效用函數及其梯度。博弈論為研究人員提供了一個新的視角來看待赫布法則,同時也為一系列機器學習問題提出了解法。

圖8. 多主體建模的視角,為基于優化和基于連接主義這兩種機器學習的模式搭建了溝通的橋梁
如何看待機器學習,存在一個連續的曲線,其一端是提出一個可優化的目標函數:利用凸和非凸優化理論來解決問題,該方向可以找出解決方案的整體性質。而在另一端上,是由神經科學引發的純聯結主義方法——例如赫布式的連接更新法則。但該方法會使得對整個系統的分析更加困難,常常需要對系統的復雜動力學進行研究。
像特征游戲這樣的基于博弈論的方法介于兩者之間。玩家的更新不受限于某個特定函數的梯度,只是對其他玩家當前策略的最佳反應。每個人可以自由地設計效用函數程序,以及更新中所需的特定屬性(例如,指定特定方向上的進行無偏的更新,或某方向的更新需要加速);同時, 多主體游戲符合納什均衡這一特性,仍然允許玩家對系統進行整體的分析。
特征值游戲代表了一個通過設計多主體游戲,來解決機器學習問題的具體例子,其解決方案,是一個大型多智能體系統的輸出。一般來說,將機器學習問題設計為多智能體博弈是一個具有挑戰性的機制設計問題,然而,研究人員已經利用兩人間的零和博弈,來解決機器學習問題。最值得注意成果就是生成性對抗性網絡(GANs)這一建模方法的成功。這推動了人們對博弈論與機器學習之間關系的興趣。
特征值游戲超越了兩人間的零和游戲,其采用了更復雜的多玩家,正和博弈的設置。這使得算法具有了更好的并行性,從而可實現在更大數據集上的可擴展性和速度優勢。它還為機器學習研究者提供了一個可量化的基線,以測試新的多主體建模在更豐富的領域——如外交和足球上的應用。
該文作者希望能經由特征值游戲,鼓勵其他人探索設計算法、智能主體和智能系統的新方向。期待未來能找出還有什么其他問題,可以被定義為游戲。同時希望該研究能進一步提高人們對多智能體的智能本質的理解。
來源:
https://deepmind.com/blog/article/EigenGame
復雜科學最新論文
集智斑圖頂刊論文速遞欄目上線以來,持續收錄來自Nature、Science等頂刊的最新論文,追蹤復雜系統、網絡科學、計算社會科學等領域的前沿進展。現在正式推出訂閱功能,每周通過微信服務號「集智斑圖」推送論文信息。掃描下方二維碼即可一鍵訂閱:
原標題:《Deepmind最新成果:博弈論視角下的主成分分析》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

