- +1
算法祛魅②|放不下手機的我們,也被困在了算法里
【編前語】
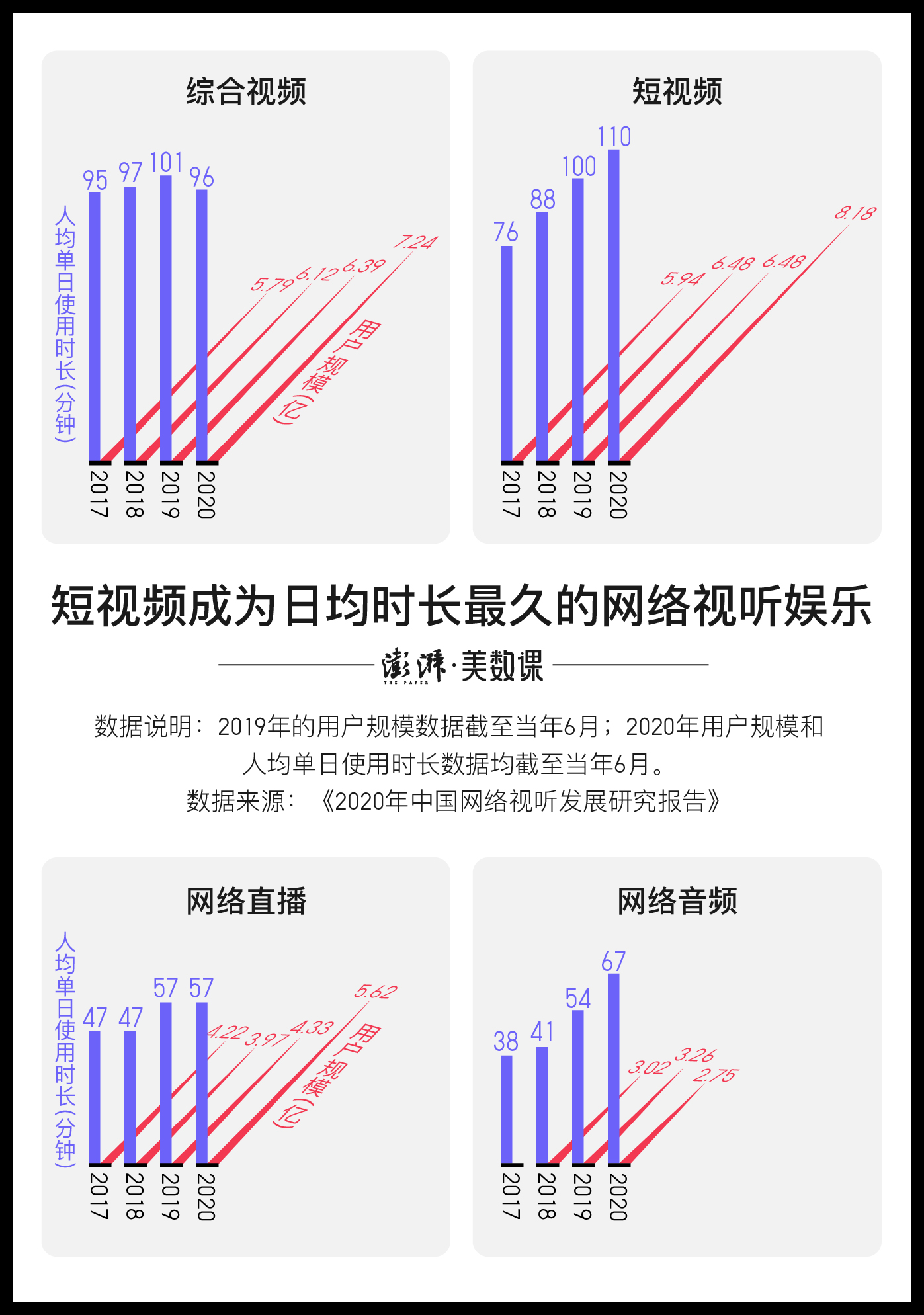
據今年人民網發布的《2020中國網絡視聽發展研究報告》統計,截至6月份,我國短視頻用戶規模達到8.18億,人均單日時間達110分鐘,近兩成用戶每天看短視頻2小時以上。短視頻產業的繁榮成為了新的資本焦點,但也不免讓人產生新的憂慮。今年上映的紀錄片《社交困境》就指出了類似的問題,隨著推薦算法的不斷強大,作為受眾的我們越來越難放下眼前的手機,不斷地重復著相同的滑動動作,眨眼間消耗掉大把的時間。
澎湃新聞和互聯網資深軟件工程師Justin聊了聊,請他為我們普及一下推薦算法背后的機制。Justin認為,推薦算法的初衷是為了提高人們的閱讀效率,但互聯網公司為了能更多地吸引用戶,把推薦算法變成了一種工具,解決了算力的同時,也加強了社交產品中原先就容易讓人上癮的特質。可惜的是,目前從社會層面上,這個問題很難得到抑制。作為用戶的我們,要有意識地去觀察自己的使用行為,不能讓自己的時間被無意義地吞噬。

“人類在沉迷,機器在學習。”來源:Instagram @ml.india
澎湃新聞:在沒有推薦算法前,網站是怎么推薦內容的?
Justin:在以前,傳統的做法是根據規則過濾內容,比如說根據熱度推薦,某個視頻在本站的熱度很高,那我就給你推薦;如果不高,就不推薦。或者說,如果你曾經點贊過很多生活區的視頻,那就給你推薦生活區的視頻,其他的我就不管了。這些都是很單一的明確的判斷標準。
澎湃新聞:那推薦算法又是一個什么樣的機制呢?
Justin:簡單而言,推薦算法就是把一堆用人話講出來的目標,轉化成機器能夠理解并運算的數字。在大數據統計的基礎上,這個算法會提取用戶和內容這兩者的特征,經過一系列復雜的轉換和計算后,給用戶匹配到合適的內容。
舉個例子,我們把用戶的年齡、性別、注冊時間、歷史點贊行為等數據特征化,作為模型的輸入。這些數據的維度通常非常多,但如果我們簡化為一個二維空間,就是一個個平面上的點。推薦算法就是要用一根不規則的曲線去不斷地擬合這些點,去尋找最佳匹配,慢慢地也就成為了一個復雜的算法。
澎湃新聞:你之前在播客《楓言楓語》中提到過,因為推薦算法的操作太簡單了,所以算法工程師反而不太好控制,甚至會嘲笑自己是調參工程師。這個觀點會不會和上面提到的推薦算法的復雜性產生沖突?
Justin:這可能是我之前在節目里表達得不夠準確。簡單是指的應用層面,而復雜則是設計層面。也不是說應用層面的算法工程師能力不強,畢竟計算機科學工業已經發展了這么多年,肯定會出現許多精細化的領域分工,大家都是各有所長的。
澎湃新聞:那“調參工程師”這個說法又是怎么來的呢?
Justin:對于應用的工程師來說,他們主要是把這個算法現有的模型拿到線上使用,也就是一個輸入加一個輸出。雖然沒有我描述得這么簡單,但總的來說,你可以理解為這個算法的中間是一個黑盒,就是一個fx函數,假設它里面是x加x的話,你輸入一,就會得到二,對吧?也就是說,無論輸入是怎樣的,輸出是肯定不會變的。
而且因為中間這個部分是黑盒,你根本不知道它是怎么運作的,甚至連設計算法的那個人,他可能也不好拍板,說這里輸入一個什么東西后,一定會得到一個什么效果,所以我才說這個算法不是特別好控制。就好比,大腦的最小組成單位是一個神經元,神經元會釋放很多不同的神經遞質,然后產生一些化學反應。你能理解神經元是怎么運作的,你就能完全明白我們的意識是怎么產生的嗎?不可以,這是兩個不同的維度。尤其當推薦算法正式上線的時候,它將面對一個裝有幾億甚至幾十億用戶的龐大沙盤,最后這個群體會變成什么樣子,我們是不可預知的。
澎湃新聞:所以推薦算法工程師每天就是在控制參數嗎?他們的工作內容是怎樣的,可以舉個例子嗎?
Justin:舉個例子,如果我們的目標很明確是要讓某一類型內容(feed)的點贊率上升,那我們可以先撈一撥用戶出來,作為實驗組,然后再撈一批用戶作為對照組,通過很科學的方式驗證這個算法實驗的操作是否正確。
之后,我再對這些用戶和內容特征做一個不同權重的設計,把這些特征輸入我們的模型后,就可以通過調參得到不同的目標:比如推一個內容(feed),就是為了讓你點贊,或者就是為了讓你評論等等。
實驗之后,我發現之前調的那些東西是對的,那就說明我做對了。但至于我是怎么做對的,我也只是猜測,我不確定我寫了這些東西之后,它到底能不能得到這樣的結果,甚至可能會發生這樣的小概率事件:我的實驗結果是對的,但在全網鋪開后,這個算法模型反而起到了反效果。這是因為推薦算法真正難的地方在于,很多時候你的目標是不可量化的,而我們只能通過其他多個可量化的指標去逼近這個不可量化的指標。
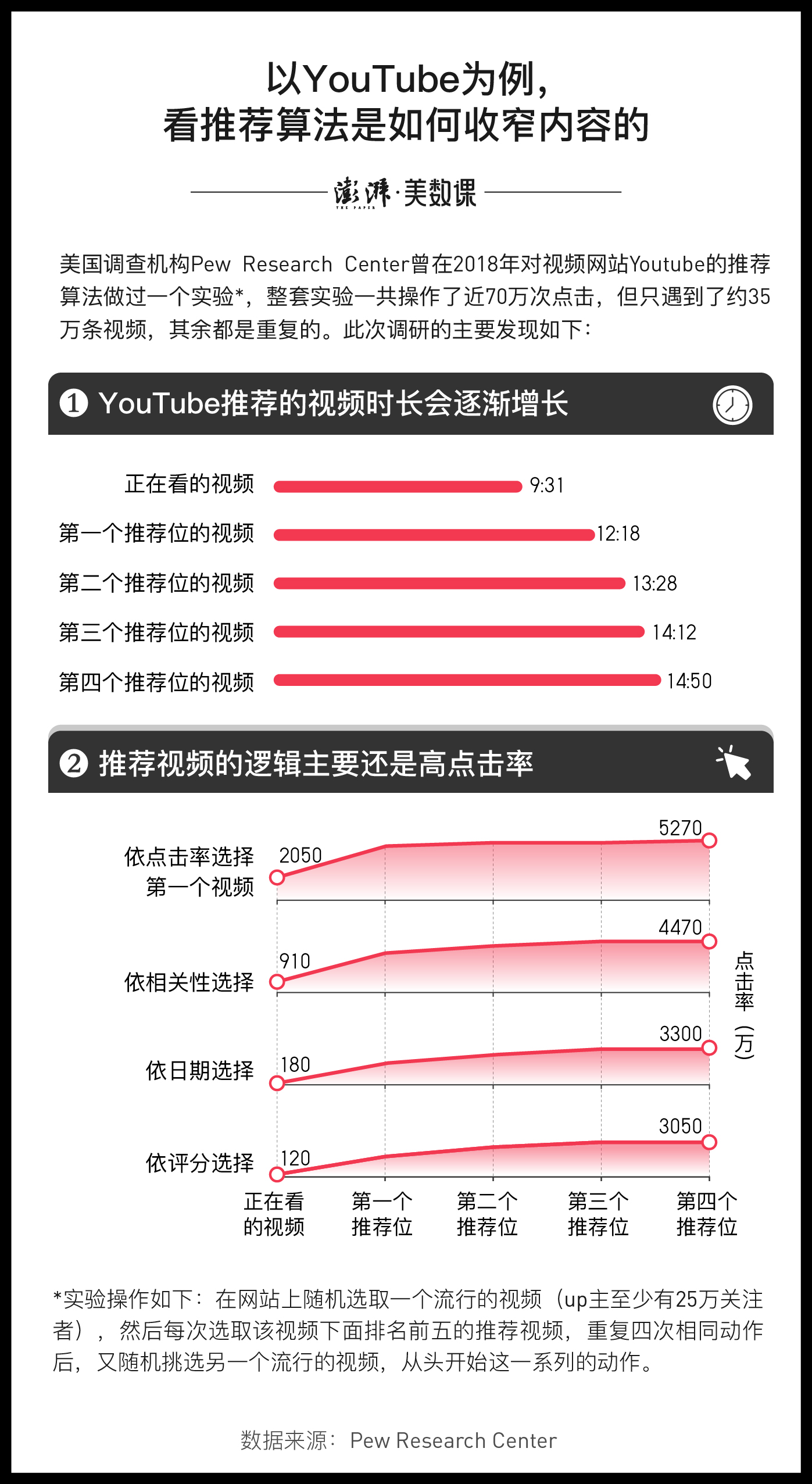
澎湃新聞:你之前還提到了一個觀點:推薦算法的弊端在于,它沒法保證推送給我喜歡內容的同時,還讓我學到新東西。為什么出現這個問題呢?
Justin:這其實是機器解決人類問題所面對的一個非常大的難點。機器的目標通常是非常明確的,而我們想學到的東西,常常是不可量化的。
學習新知識,需要的是發散思維,需要不斷地拓寬認知領域,但純靠機器推薦的話,它的趨勢肯定是收斂的。比如我在ins上點贊了一些美女和賽博朋克風格的照片,那它一定會繼續給我推薦這兩種照片。如果機器想幫助我拓寬認知邊界,那它一定得想辦法在里面塞更多的東西,而且不能是美女或賽博朋克。換言之,它只能猜測。
因此,現在抖音、快手等內容平臺會加入很多機器推薦之外的策略。比如通過和你背景相似的群體的喜好,去試探你喜歡的內容,如果你點擊了喜歡,那你的歷史數據就會被慢慢改變了。還有人工干預,比如新出了一個綜藝,熱度不夠的話,機器肯定是無法預知的,就需要人工把這個內容推向全網。
澎湃新聞:那可以說,推薦算法是導致人們不斷沉迷手機的罪魁禍首嗎?
Justin:不一定。手機成癮本身的根源并不在于推薦算法,推薦算法僅僅是一種新型的技術手段,它極大地解決了算力問題,助長了原先就存在于社交產品中的那些特質。畢竟,每天起床去健身房的人是少數,每天堅持閱讀的人也是少數,絕大多數人可能更喜歡被投喂信息的方式。
在推薦算法沒出來前,人們也需要花很多時間去閱讀內容。大概在2010年前后,推特已經有上億用戶,每名用戶關注的人數也超過了百位,如果一百個人每天發三條推特,按照傳統的時間排序,用戶如果想看到高質量的內容,就只能往上翻,翻完這300條推特,這個閱讀效率是很低的。推薦算法的出現,能幫助讀者快速地完成閱讀,以免被淹沒在90%的無意義聒噪中。
我始終認為技術本身是中立的,它產生的時候就是單純地為了解決一個技術難題,而不是為了讓一些公司做A/B測試。至于它解決了難題后,未來會變成什么樣,這并不是技術在發展的過程中它所會去考慮的。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

